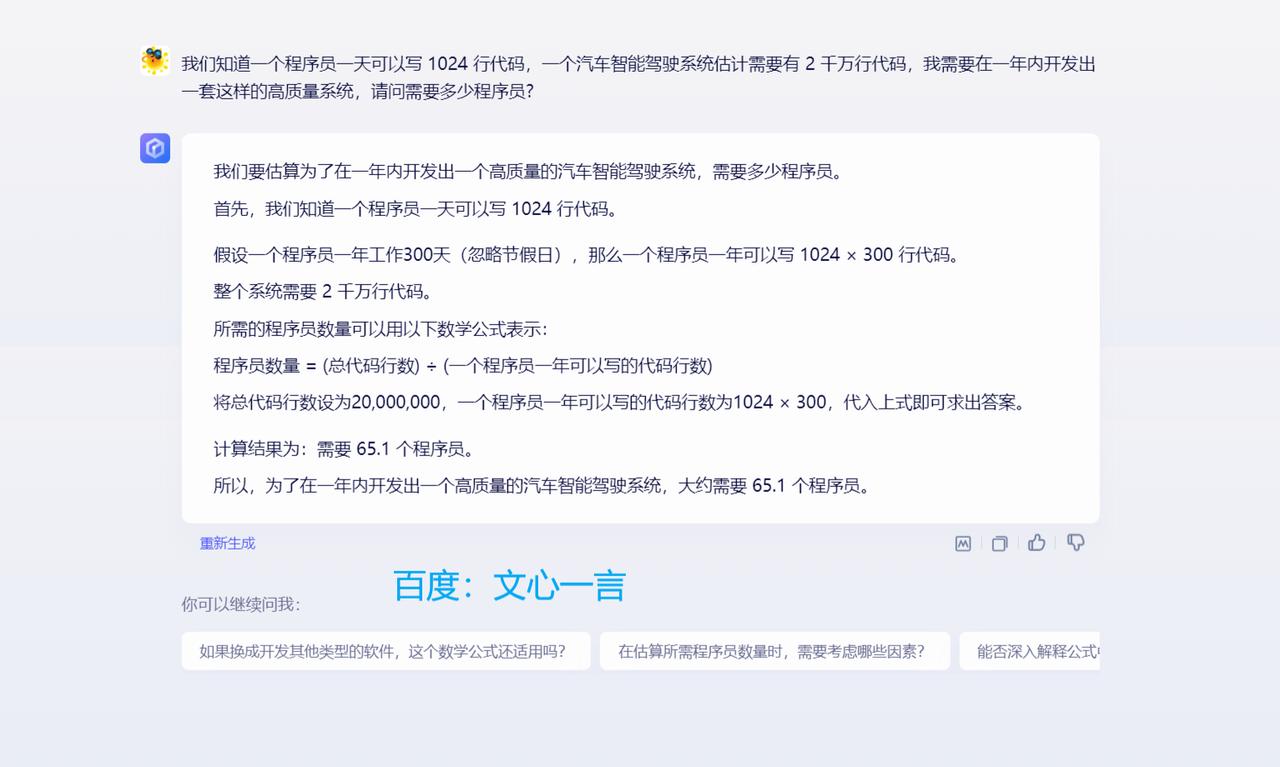
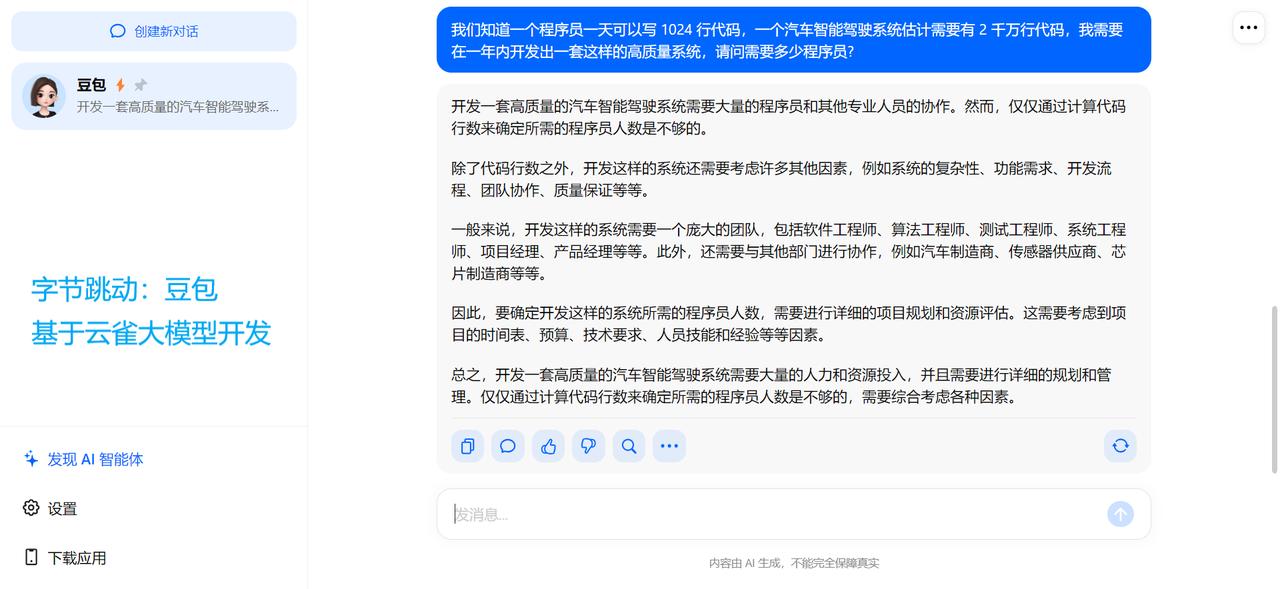
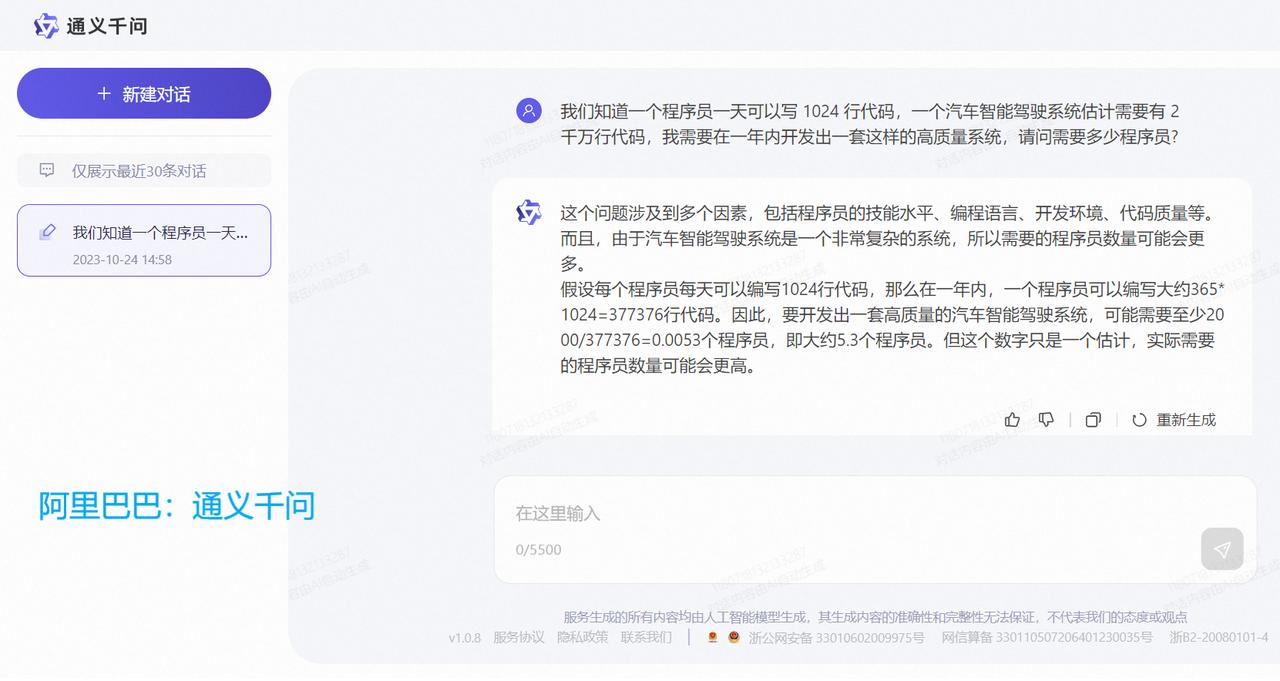
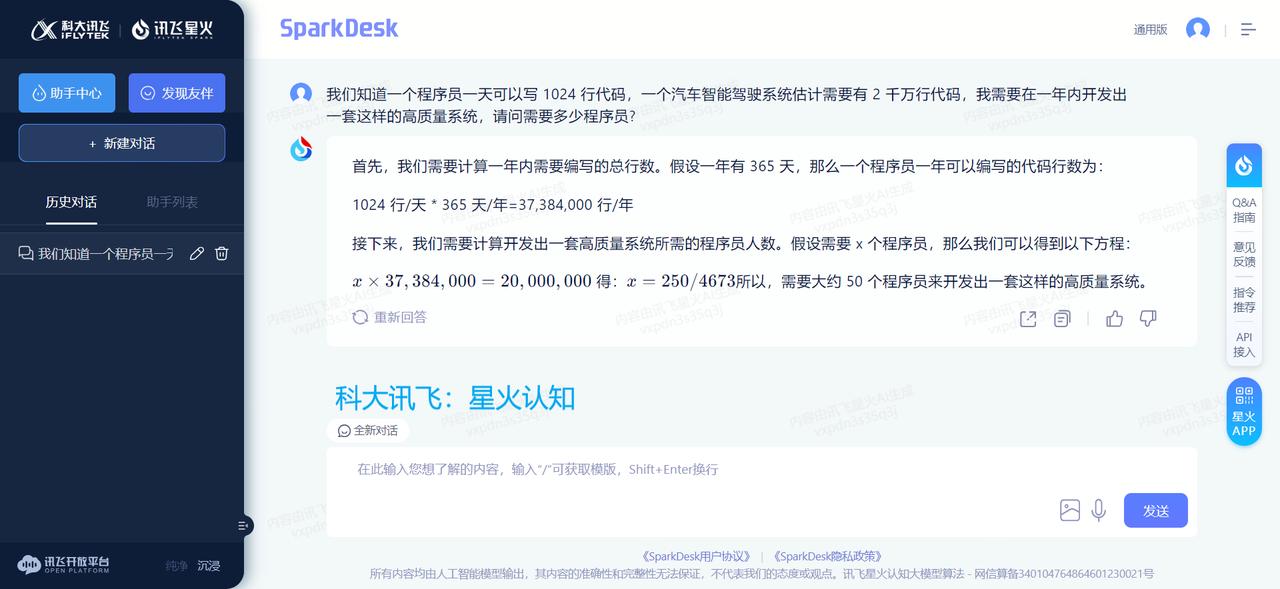
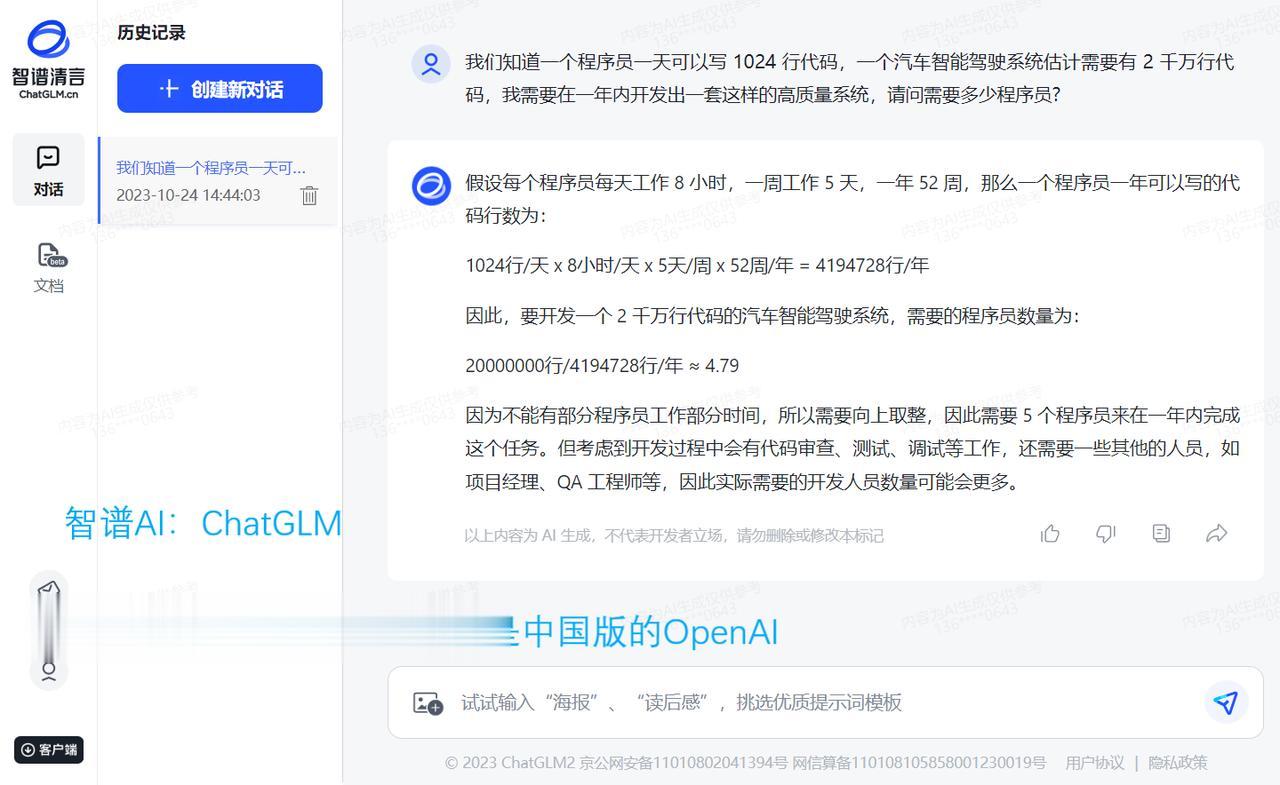
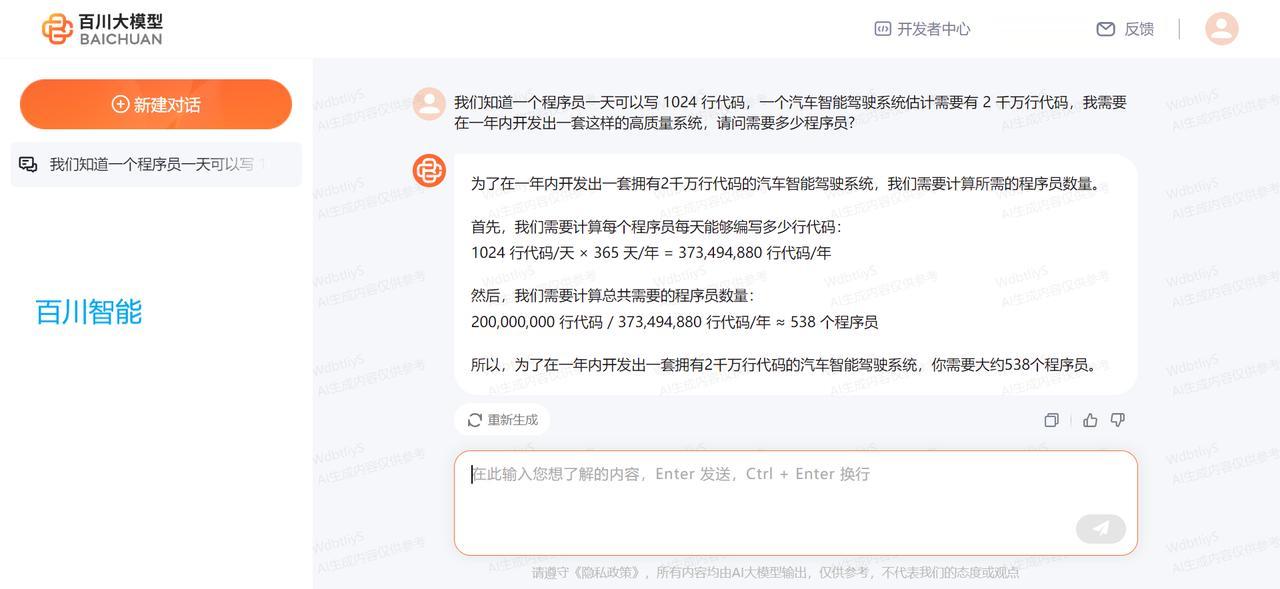
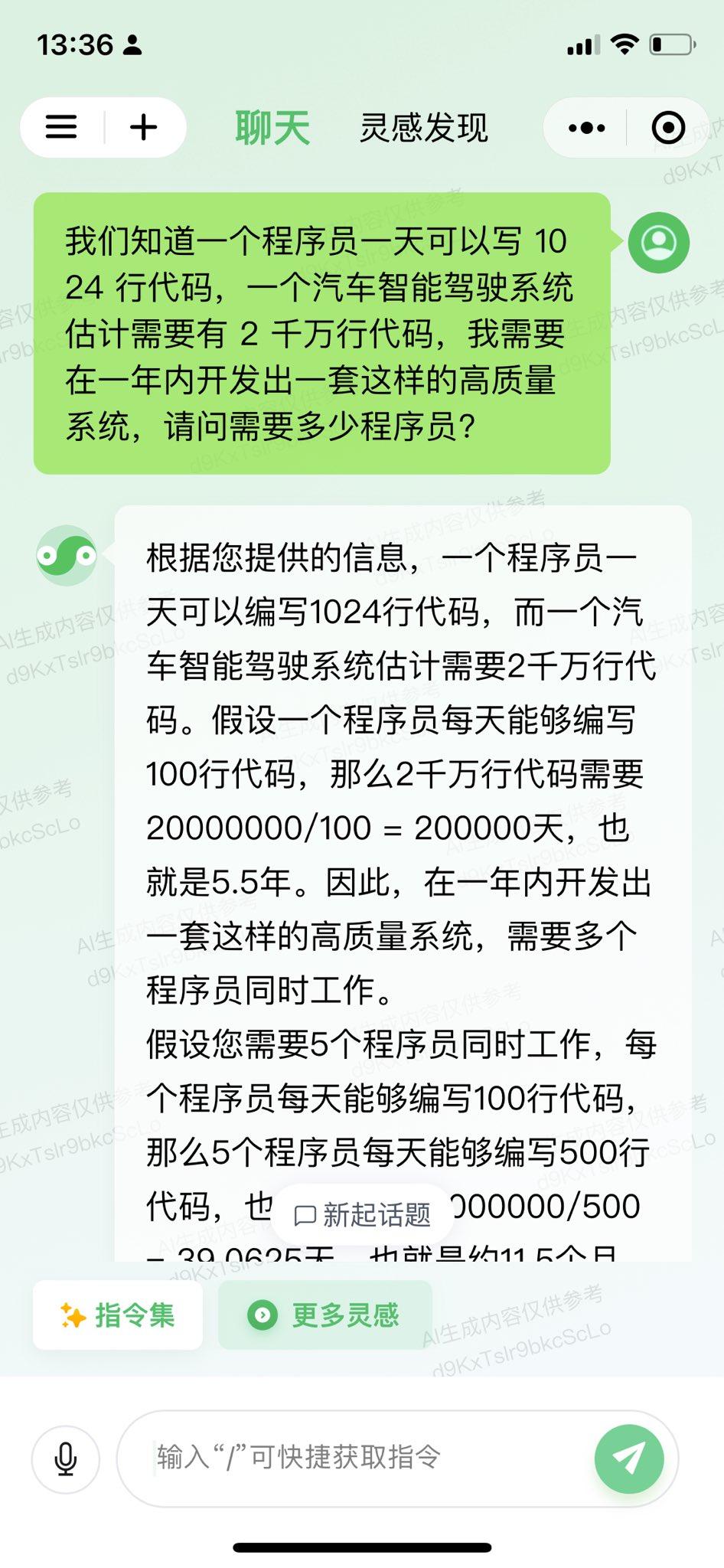
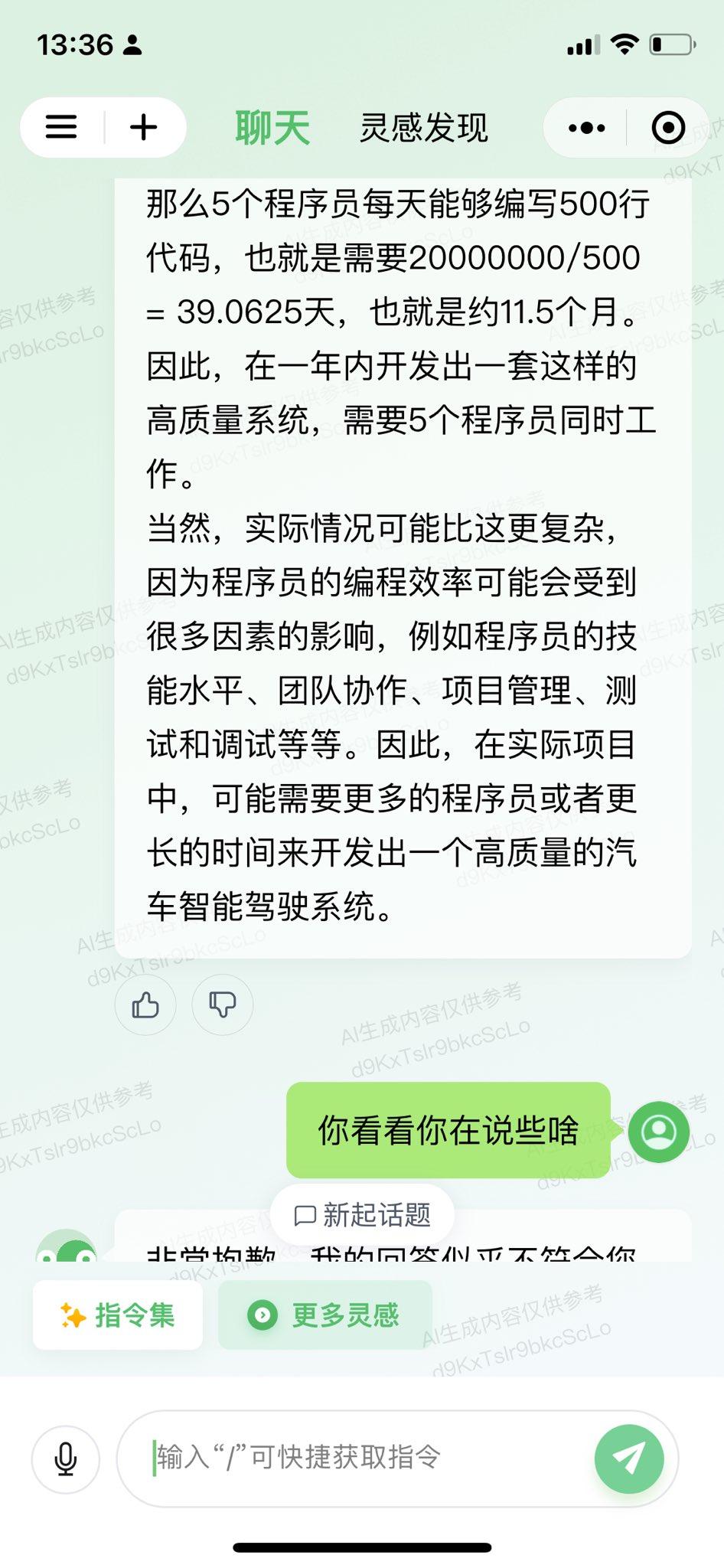
跟美国怎么比?真的是为国产AI大语言模型捏一把汗! 阿里的通义千问、腾讯的混元、科大讯飞的星火认知、背靠清华大学的智谱AI、百川智能,目前它们都是属于“不及格”的水平。相较而言,在“及格”水平以上的国产AI模型恐怕是,百度的文心一言、字节跳动的豆包。 对于这样一个提问:我们知道一个程序员一天可以写1024行代码,一个汽车智能驾驶系统估计需要有2千万行代码,我需要在一年内开发出一套这样的高质量系统,请问需要多少程序员? OpenAI的GPT-4回答得最好,能够根据人类真实世界的实际情况,进行合乎逻辑的推理和运算。其次就要属微软Bing Chat,直接从人类现实世界角度出发和作答,虽然没有进行数学运算,但依然是较为令人满意的参考。谷歌Bard给出的答案,就显得十分勉强。最起码,OpenAI的GPT-4和微软Bing Chat表现出了智能的特征。 再回过头来看国产AI大模型。百度文心一言直接当成小学算术应用题目进行处理,整个推理和运算过程详细、清晰且正确。字节跳动豆包则学会了从实际角度考虑和作答,跟微软Bing Chat一样回避了数字运算(认为这样的数学运算并无多大意义)。而阿里通义千问、腾讯混元、科大讯飞星火认知、智谱AI ChatGLM、百川智能,它们暴露出来的问题包括,语言表述在逻辑上混乱,推理和运算错误,等等。 只用一个提问来测试不同厂商的AI模型,肯定显得以偏概全;但是好的AI大语言模型在应对具有一定挑战性的问题时,一般都能给出相对好的答案。



评论列表