DeepSeek又一次让外国人感到震惊——其开源的全新模型Math V2,不仅首次将AI的数学能力推至世界第一,拿下国际数学奥林匹克(IMO)金牌,还将全球主流数学AI模型逐一碾压了一遍。
更关键的是,这款创下纪录的模型全程开源,这意味着中国AI在数学推理领域,实现了从“跟跑”到“领跑”的真正跨越。

答案并非“能做对更多数学题”,而是它开始像真正的数学家一样思考和推理。
DeepSeek Math V2有两颗“脑子”:一颗负责“大胆假设”的生成器;另一颗负责“小心求证”的验证器。
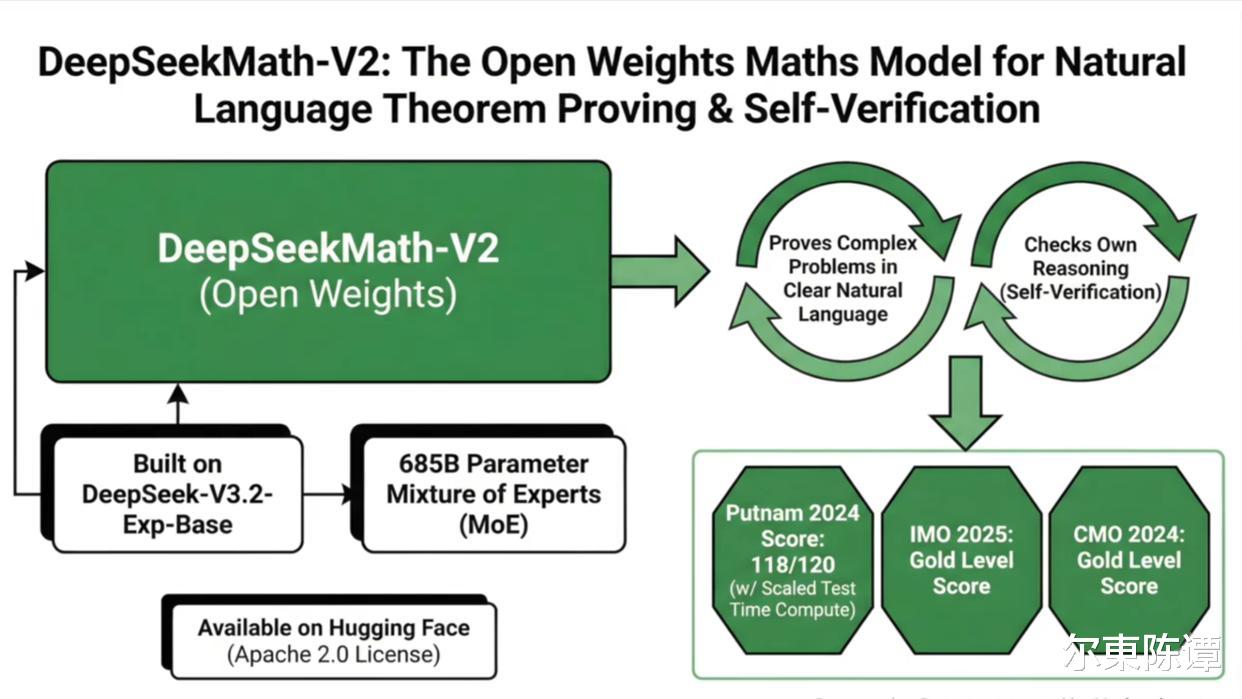
在此之前,AI做数学题更像小学生应付作业——算对了就过,算错了就随便编个答案糊弄过去。但Math V2完全不同,它会自己检查答案、给解题过程打分,发现错误就推翻重来,直到推理逻辑完全通顺。
这正是数学AI最难突破的关卡:不只是算出正确答案,更要走对完整的推理路径。
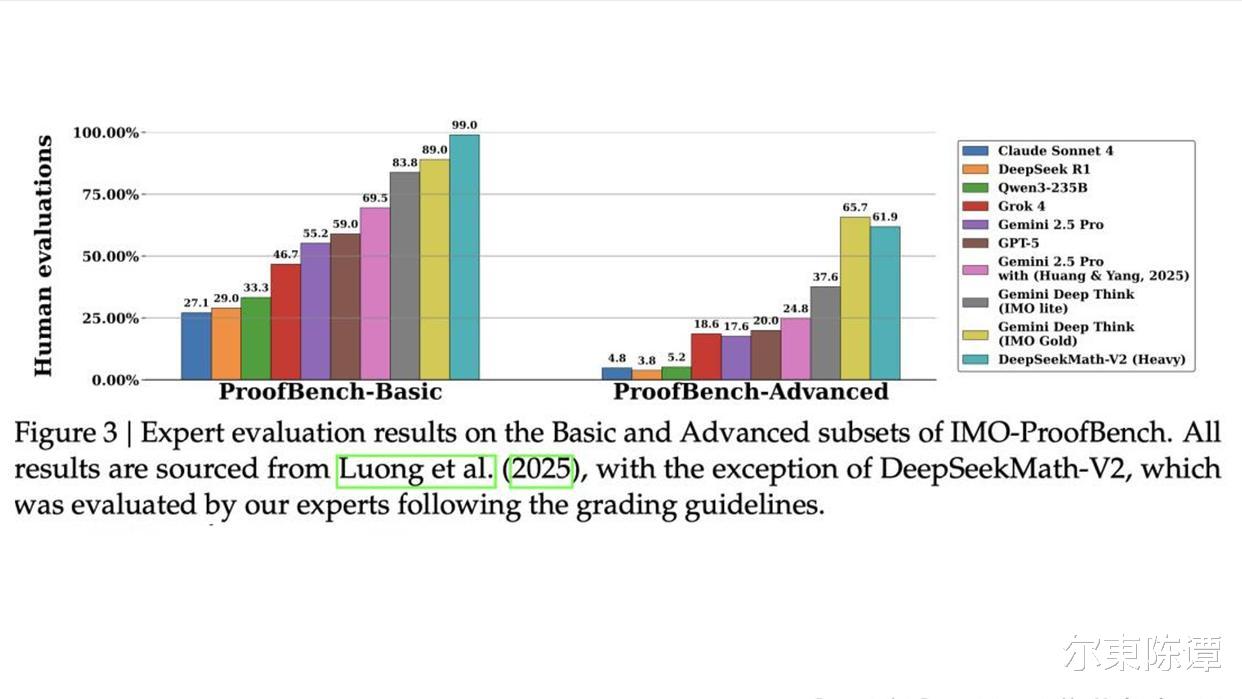
再看核心能力的比拼,这款模型的表现堪称亮眼:代数能力超过GPT-5,几何推理能力约为Gemini 2.5 Pro的3倍,甚至直接打穿了IMO金牌的评分线。一款开源模型能做到闭源模型都达不到的高度,说它是数学AI领域的“卷王”毫不为过。

它的意义远不止“AI会做数学题”这么简单。数学从来不是单纯的“解题工具”,而是检验AI推理能力的试金石——谁能在数学上实现突破,谁就离真正的强人工智能更近一步。这也是中国AI模型,第一次在全球最硬核、最考验真本事的AI指标上,实现了正面领先。
更值得骄傲的是,这份成绩是在美国对我国算力技术封锁的背景下取得的。DeepSeek没有依靠堆砌参数、玩“话术幻觉”的小聪明,而是凭借自主创新的技术,战胜了算力资源充足的美国AI团队。硬指标、硬逻辑、硬实力,成了这次突破的关键词。
或许很多人还没意识到,这件事背后的含金量到底有多高。
数学推理是谷歌、OpenAI等美国科技巨头最引以为傲的核心技术,也是他们最不愿对外开源的“压箱底本领”。而DeepSeek不仅攻克了这一技术难题,还将所有成果全部开源,这一系列的举动,恐怕要直接改写全球AI领域的竞争格局了。
因为,开源的决定,意味着三件前所未有的事:
第一,中国首次在AI的“基础科学能力”上实现突破。这次突破不是停留在应用层面的功能优化,而是触达了AI底层的推理结构,为后续技术发展打下了坚实基础。
第二,中国AI技术的扩散速度将远超美国模型。谷歌等企业还在闭门研发,而DeepSeek的开源让国内所有科研团队和企业都能参与技术迭代,形成“全网一起打磨技术”的局面。
第三,全球可能首次出现这样的趋势:在AI推理领域,中国模型成为行业基准,美国模型需要向我们的标准对齐。这在十年前,是完全无法想象的事。
所以,DeepSeek Math V2的出现,绝不是“数学模型的小幅度升级”。它第一次从美国手中,撕开了强人工智能核心能力的缺口,也标志着AI竞赛的下半场,中国科企正在真正进入主场。

那么你觉得,这是不是中国AI发展的一个重要拐点?欢迎大家在评论区留下自己的看法。