嵌入(Embedding)是RAG流程里非常关键的一个步骤。它处理的是数据提取和分块之后的内容,嵌入的好坏直接影响系统能不能准确地表示和检索信息。这篇文章会讲清楚嵌入是什么、怎么工作的,还有怎么挑选合适的模型。
经典的RAG工作流典型的RAG流程包含这几步:
首先是数据提取,从文档、网站、数据库等数据来源收集文本。然后分块,把文本切成更小但有意义的单元,并且要保持上下文完整。接着就需要嵌入处理,把每个分块转成固定长度的数值向量。然后向量存储这步把嵌入放进向量数据库,常用的有FAISS、Weaviate、Pinecone这些。
最后是检索和生成。用户查询进来后,先把查询嵌入,找到语义相似的向量,再用这些向量生成回答。
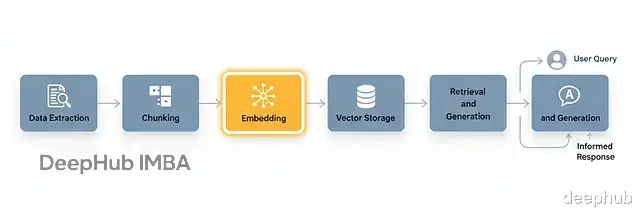
嵌入步骤保证了语义相似的文本在向量空间里位置相近,这样检索就不是简单的关键词匹配,而是基于实际含义。
向量空间表示的基本原理嵌入模型做的事情是把输入文本变成向量——一串代表语义含义的浮点数。这个向量存在于高维空间,距离远近反映相似程度。
相似句子的向量靠得近,不相似的就隔得远。
举个例子:
"AI helps companies innovate"和"Artificial intelligence supports business automation"
用词完全不一样,但表达的意思接近,生成的向量也就相近。这种几何表示让检索系统可以用余弦相似度或点积来衡量语义距离。
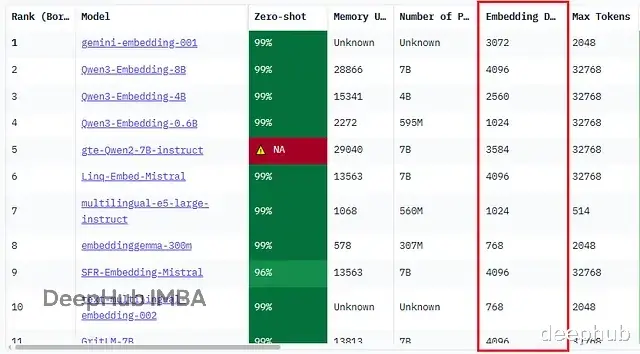
嵌入模型的关键参数选模型时几个技术指标很重要:输入序列长度、输出维度、归一化方式、批处理能力。
Hugging Face的MTEB(Massive Text Embedding Benchmark)基准测试把这些参数都列得很清楚,方便对比不同模型在各类任务上的表现,也能看出它们怎么处理语义相似性、检索和多语言场景。

这个参数决定模型一次能处理多少token。分块超过这个限制就得截断或者再切小,所以它也暗示了最优分块大小。分块太长被截断了,上下文丢失会影响检索质量。
输出维度就是每个嵌入向量里数值的个数。常见的有384、768、1024、1536、2048这些,取决于模型架构。
高维嵌入能捕捉更丰富细腻的语义关系,检索准确率会提升,代价是存储成本高、向量搜索变慢。低维嵌入在大规模检索时更快更省资源,但语义深度和精度会打折扣。
有些模型输出的向量已经归一化了(长度为1),直接算余弦相似度很方便。但也有模型输出未归一化的向量,索引前得手动归一化。不归一化的话,向量数据库可能把向量大小差异当成语义距离,导致相似度分数不准。
批处理能力支持批量推理的模型能同时处理多个分块,对大规模RAG流程的吞吐量提升明显。
常用的开源嵌入模型搞清楚向量是什么、嵌入怎么工作之后,可以看看具体有哪些开源模型可用。这些模型架构、维度、多语言支持各不相同,但目的都一样:把文本变成有意义的数值表示,驱动语义搜索和知识检索。
几个下载量和benchmark表现都不错的开源模型:
all-MiniLM-L6-v2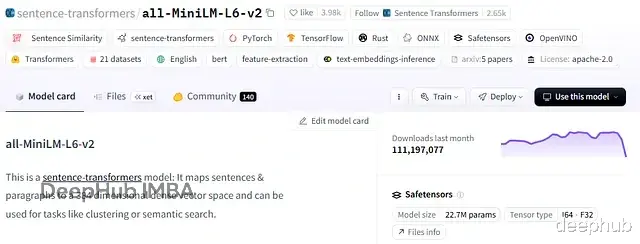
维度: 384性能: 处理短到中等长度文本速度快,效率高用例: 低延迟生产系统,成本敏感的检索任务评价: 体积小但语义关系捕捉能力够用
使用方式(Sentence-Transformers):
pip install -U sentence-transformers from sentence_transformers import SentenceTransformer sentences = ["This is an example sentence", "Each sentence is converted"] model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2') embeddings = model.encode(sentences) print(embeddings)
all-mpnet-base-v2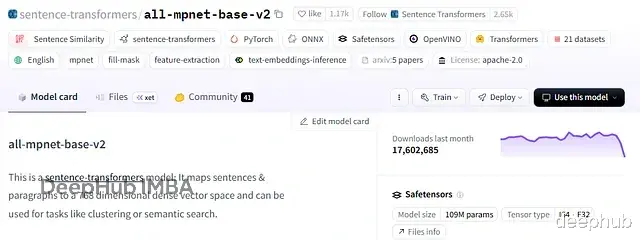
维度: 768性能: 上下文理解能力强,嵌入质量高用例: 通用语义搜索和聚类评价: 准确性和速度平衡得不错
使用方式(Sentence-Transformers):
pip install -U sentence-transformers from sentence_transformers import SentenceTransformer sentences = ["This is an example sentence", "Each sentence is converted"] model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2') embeddings = model.encode(sentences) print(embeddings)
Jina Embeddings v3
支持100多种语言,上下文窗口大。短文档和长文档都能保持稳定表现。
维度: 可配置(512–1024)性能: 最长支持8000 token,多语言覆盖广用例: 大规模语义搜索、RAG、混合检索系统评价: 可扩展性和质量平衡做得好
使用方式(Sentence-Transformers):
!pip install -U sentence-transformers from sentence_transformers import SentenceTransformer model = SentenceTransformer("jinaai/jina-embeddings-v3", trust_remote_code=True) task = "retrieval.query" embeddings = model.encode( ["What is the weather like in Berlin today?"], task=task, prompt_name=task, )
multilingual E5 (e5-base-v2)跨语言的准确性和效率比较均衡,适合多语言语义检索和问答系统。
使用方式(Sentence-Transformers):
pip install sentence_transformers~=2.2.2 from sentence_transformers import SentenceTransformer model = SentenceTransformer('intfloat/multilingual-e5-base') input_texts = [ 'query: how much protein should a female eat', 'query: 南瓜的家常做法', "passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.", "passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅" ] embeddings = model.encode(input_texts, normalize_embeddings=True)
模型选择选哪个嵌入模型得看分块大小、内存限制和具体用例。
分块大小和输入长度 大分块需要token限制高的模型,避免截断导致上下文丢失。
内存和维度 高维嵌入(1024–2048)语义更丰富但占内存、搜索慢;低维(384–768)更快更轻但语义深度有损失。
语言支持 英语数据用MiniLM或MPNet就够了;多语言任务Jina v3、EmbeddingGemma、E5这些更合适
可扩展性 批处理和动态维度嵌入(Matryoshka)能帮助高效处理大数据集。
好的模型要在准确性、效率和系统约束之间找到平衡,契合RAG流程的实际需求。说白了,RAG系统的智能程度取决于嵌入的质量。
总结嵌入这一步把非结构化文本转成结构化的、有语义含义的向量,这是RAG系统智能检索的基础。
英语数据集用MiniLM和MPNet还是靠谱的。多语言或阿拉伯语数据就得用Jina Embeddings或E5这种跨语言理解能力强的模型。
嵌入让文本变成可处理的数据,让含义变得可测量。RAG系统的强弱取决于它依赖的嵌入质量。
https://avoid.overfit.cn/post/8224fc3532aa44e588d9882d16e2b6b2
作者:Ahmed Boulahia