《科创板日报》报道:芯片的运算速度比英伟达的GPU快了10倍,而成本却只有前者的十分之一。一个大型模型的产生速度几乎达到了500个tokens/s/s,远远超过了 ChatGPT (3.5是40个 tokens/s)。
Groq和马斯克的“Grok”很像,但它的诞生要比 Grok早得多。它创建于2016年,是一个人工智能的解决方案公司。
Groq公司的创始人中,有八个人都是谷歌早期开发TPU的核心团队,他们只有10个人。比如,在他加入谷歌X快速分析小组,为谷歌的母公司 Alphabet设计和培育了新的 Bets之前, Groq的创立者和首席执行官 Jonathan Ross负责了原来的 TPU芯片的核心部件,并且在此之前,他还参与到了 GoogleX快速分析小组中。

尽管这个小组是从谷歌的 TPU衍生出来的,但是 Groq并没有在 TPU和 CPU的道路上走下去。Groq采用了一种全新的体系结构,即语言处理单元(LPU)。
Groq说:“我们所做的并不是一个大规模的模型,而是一个全新的端对端处理器系统,它可以为诸如人工智能大数据这样的计算密集型应用提供最快速的推理能力。”
由此可以很容易地看到,Groq公司的产品侧重于“速度”,而“推理”则是它的主攻方向。
Groq确实做得很“快”,据 Anyscale LLMPerf排名,lama270B运行在 GroqLPU推断引擎上,它的输出 tokens吞吐率比其它任何一个云推断提供商都要快18倍。
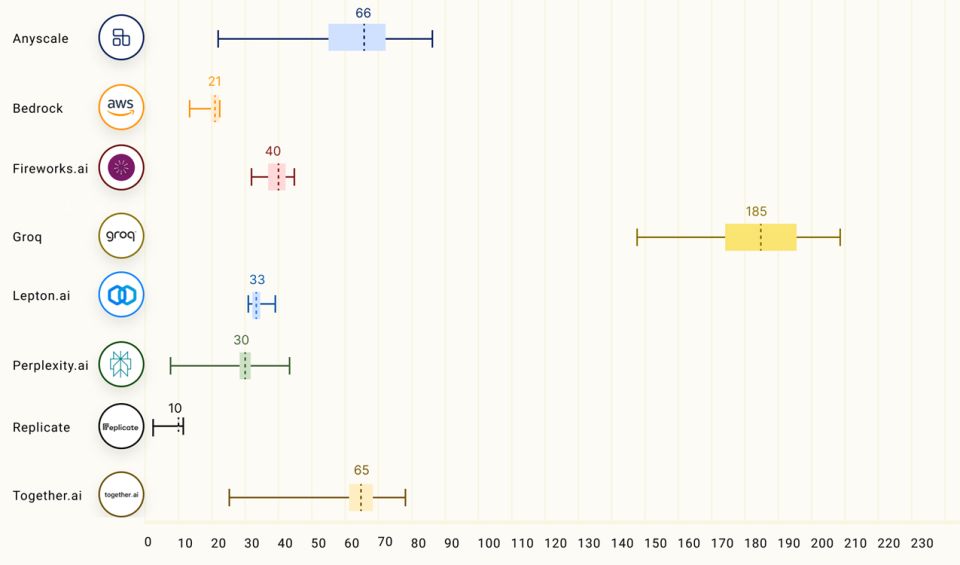
第三方机构Artificialanalysis.ai对 Groq进行了评估,结果表明 Groq在处理能力方面可谓“遥遥领先”。

为了验证自己的芯片性能, Groq也在其官方网站上公布了一项大型软件的免费版本,其中有Mixtral8×7B-32K,Llama2-70B-4K,以及 Mistral 7B-8K,其中前两个已经投入运行。

图| Groq (lama 2)对照 ChatGPT
LPU的目标是突破计算密度与存储带宽这两大模型的瓶颈。根据 Groq的说法,对于 LLM, LPU具有比 GPU/CPU更强的运算能力,使得每一个字的运算速度都会大大降低,并且产生的文字序列也会更快。同时,该算法还克服了外部存储瓶颈,使得其在大规模计算环境下的计算效率优于GPU。
据了解, Groq芯片并没有使用英伟达GPU所依赖的HBM和CoWoS封装,而是使用了14nm工艺,拥有230MB的SRAM,80TB每秒的存储空间。在计算能力上,它的整数(8比特)计算速度可以达到750 TOPs,而浮点(16比特)计算速度可以达到188 TFLOPs。
很明显,“快”是Groq的主要优势,这是它所采用的SRAM中的一个亮点。
SRAM是当前速度最快的一种存储器,但是它的成本很高,所以只有在 CPU一级缓冲和二级缓冲等条件下才能用到。
华西证券表示,目前能够应用于存-算一体化的内存产品包括 NAND闪存, SRAM,动态随机存取存储器,随机存取存储器(RRAM),以及 MRAM。SRAM在这三种存储器中,由于其在运算速度、能量效率等方面的优越性,尤其是在内存逻辑开发后,更是显示出了更高的能量效率与更高的精度。SRAM, RRAM将会是云计算的主要存储介质。

上市了没??