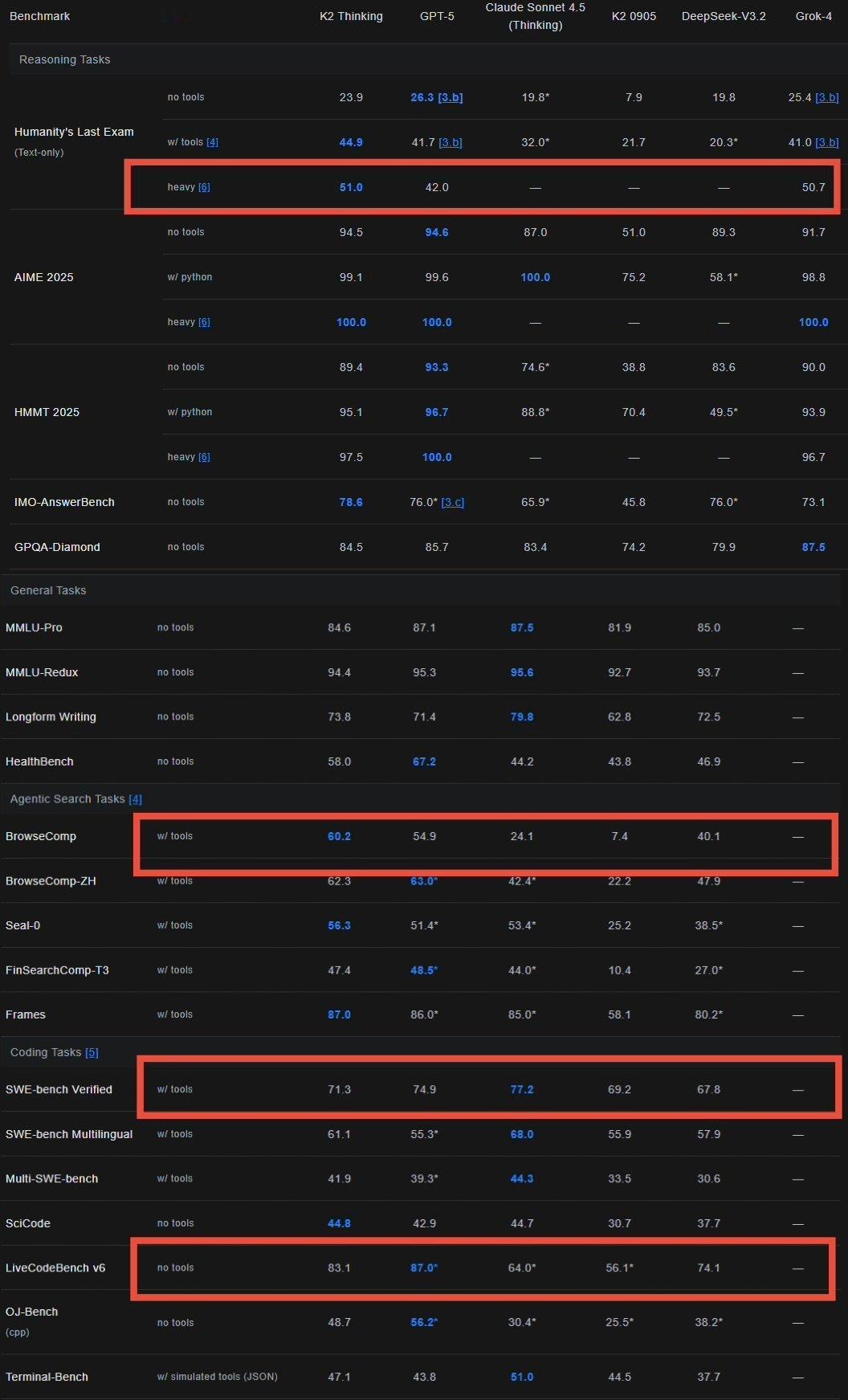
四个审稿人全给6分,NuerIPS唯一满分论文炸了!
之所以说它炸,主要是论文给出的结论实在太出人意料了——
真正决定推理上限的是基座模型本身而非强化学习,且蒸馏比强化学习更有望实现大模型自我进化。
好家伙,这无异于给正炙手可热的RLVR(可验证奖励的强化学习)迎面泼下一盆冷水~

RLVR,自大模型推理范式开启后就成为一众主流模型(如OpenAI-o1、DeepSeek-R1)的核心驱动力。
由于无需人工标注,通过自动验证奖励优化模型,它一度被视为实现模型自我进化、逼近更高推理能力的终极路径。
但来自清华上交的这篇论文,却让风向陡然生变——
如果进化的钥匙不在强化学习,那当前围绕RLVR的巨额投入与探索,意义何在?
 真正能突破推理上限:蒸馏而非强化学习
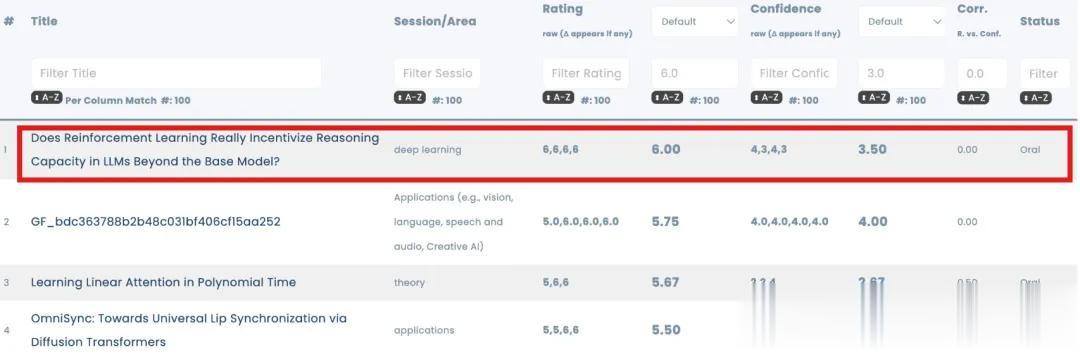
真正能突破推理上限:蒸馏而非强化学习 这篇论文题目为《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? 》,“获NuerIPS唯一满分”的结论由PaperCopilot(非官方论文分析平台)统计得出。
同时它还荣获ICML 2025 AI4Math Workshop最佳论文奖,并入选NeurIPS 2025大会口头报告。

之所以提出这项研究,主要是近年来RLVR在大语言模型中被广泛应用于提升数学、编程、视觉推理等任务的表现。
随之而来的是,AI圈普遍假设——
RLVR不但能提升推理效率,还可能扩展模型的推理能力,即让模型学会底层基础模型本来不会的新推理路径。
但问题是,这一结论真的成立吗?

于是带着疑问,来自清华上交的研究团队核心想要弄清一个问题:
RLVR是否真的让大语言模型超越其“底模”推理能力边界,还是只是优化已有能力?
而通过一系列实验,团队得出以下最新结论:
RLVR主要是在“强化”底模已有的路径,而不是“发现”底模没有的路径。 RL训练后的模型在低采样次数(如pass@1)表现更好,但随着采样次数增加(pass@64、pass@256…),底模反而能超过RL模型,这说明底模隐藏的推理能力被低估了。 多种RL算法(如PPO、GRPO、Reinforce++等)在提升采样效率方面差异不大,且与“理论上底模最大能力”相比,仍有明显差距,这说明想靠RL突破底模上限还不够。 蒸馏方法更有可能“扩展”模型的推理能力范围,因为其接收来自教师模型的新推理模式,而RLVR更受限于底模。
换句话说,与普遍认知相反,RLVR的实际作用很可能被严重高估了。
 关键评估指标:pass@k
关键评估指标:pass@k 而为了得出上述结论,他们采用了pass@k这一关键评估指标。
所谓pass@k,是指衡量一个模型在多次尝试中,至少成功一次的几率。
相比一些传统指标(如greedy decoding准确率)仅反映平均表现,它通过多轮采样揭示模型的推理边界,能更精准判断模型是否“有能力”解决问题,而非“大概率”解决问题。
具体来说,他们主要把底模、RL模型放在同一批题目上反复测试,来看模型是“真的变聪明”还是只是“更会挑答案”。
为避免实验结果的局限性,团队选取了大语言模型推理能力的三大典型应用领域,并搭配权威基准数据集,确保测试的全面性和代表性。
数学推理(GSM8K、MATH500等6个基准) 代码生成(LiveCodeBench等3个基准) 视觉推理(MathVista等2个基准)模型则以主流大语言模型家族为基础,包括Qwen2.5系列(70亿、140亿、320亿参数)和LLaMA-3.1-80亿参数模型等,并构建“基础模型 vs RLVR训练模型”的对照组合。
其中RLVR训练模型是指,分别用PPO、GRPO、Reinforce++等6种主流RLVR算法训练后的版本,形成多组平行对照。这样既能对比RLVR与基础模型的差异,也能横向比较不同RLVR算法的效果。
然后就是对不同模型在各基准任务上的pass@k指标进行多维度采集与分析。
针对每个测试样本,分别让基础模型和RLVR模型进行不同次数的采样(k值从1逐步提升至1024),记录每次采样中“至少出现一个正确结果”的概率。
随后团队重点分析两个关键规律:
一是同一k值下,RLVR模型与基础模型的pass@k差异;二是随着k值增大,两类模型pass@k曲线的变化趋势。
同时,结合模型输出的推理路径困惑度分析(perplexity)、可解问题子集比对等辅助手段,最终形成对RLVR能力的全面判断。
论文作者介绍值得一提的是,这项研究还是出自咱们国内研究人员之手。
一共8位,7位来自清华大学LeapLab,1位来自上海交通大学。
项目负责人Yang Yue (乐洋),清华大学自动化系四年级博士生。
研究方向为强化学习、世界模型、多模态大模型和具身智能,之前曾在颜水成创办的新加坡Sea AI Lab和字节跳动 Seed团队实习过。
虽然还是学生,但发表或参与发表的多篇论文均入选顶会。这当中,他以核心作者身份发表的论文《How Far is Video Generation from World Model: A Physical Law Perspective》,因探索视频模型能否学会物理规律,还被国内外众多大佬Yan Lecun,xie saining,Kevin Murphy等转发。

另一位和他贡献相同的作者Zhiqi Chen,目前为清华大学自动化工程系大三学生。
研究方向为推理密集型大语言模型的强化学习,在校期间多次获得国家奖学金。

通讯作者Gao Huang(黄高),清华大学自动化系副教授、博士生导师, LeapLab负责人。
他最知名的工作之一就是发表了论文《Densely Connected Convolutional Networks》,其中提出了经典卷积架构模型DenseNet。
该论文不仅荣获CVPR2017最佳论文,而且被编入多本深度学习著作,单篇引用量接近6万次。

其他作者中,来自清华的还有:
Rui Lu(卢睿),清华大学自动化系四年级博士生,本科毕业于姚班。 Andrew Zhao(赵启晨),清华大学自动化系博士生,本硕毕业于加拿大哥伦比亚大学和南加州大学。 Shiji Song,清华大学自动化系教授,与黄高一起负责指导本项研究。 Yang Yue (乐阳) ,和项目负责人名字同音,但由于相对低调网上暂无太多公开资料。以及唯一来自交大的Zhaokai Wan(王肇凯),目前是上海交通大学四年级博士生。
本科毕业于北京航空航天大学,同一时期还拿到了北大经济学学士学位,当前也在上海人工智能实验室通用视觉团队(OpenGVLab)实习。
对于这项研究,团队作者特意在论文主页强调:这并不是说强化学习无用了。实际上,它在一些低采样场景仍旧非常实用。

以及有网友发现,有意思的是,DeepSeek在一年前的一篇论文中也提到了相关现象。
……这些发现表明,强化学习通过使输出分布更加鲁棒来提升模型的整体表现,换言之,性能的提升似乎源于促进了正确答案出现在TopK结果中,而非源于基础能力的增强。

而这一次,结论被用论文完整论证了。
论文:https://limit-of-rlvr.github.io/
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态