众力资讯网
deephub的文章
长上下文"记忆"的舒适陷阱:为什么更多记忆不等于更可靠
2026-02-18 22:06
deephub
长上下文"记忆"的舒适陷阱:为什么更多记忆不等于更可靠
超越上下文窗口:CodeAct与RLM,两种代码驱动的LLM扩展方案
2026-02-16 22:05
deephub
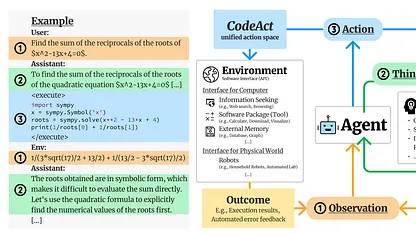
超越上下文窗口:CodeAct与RLM,两种代码驱动的LLM扩展方案
15 分钟用 FastMCP 搭建你的第一个 MCP Server(附完整代码)
2026-02-15 22:52
deephub
15 分钟用 FastMCP 搭建你的第一个 MCP Server(附完整代码)
Prompt 缓存的四种策略:从精确匹配到语义检索
2026-02-14 20:34
deephub
Prompt 缓存的四种策略:从精确匹配到语义检索
RAG 文本分块:七种主流策略的原理与适用场景
2026-02-13 21:36
deephub
RAG 文本分块:七种主流策略的原理与适用场景
LLM创造力可以被度量吗?一个基于提示词变更的探索性实验
2026-02-12 21:09
deephub
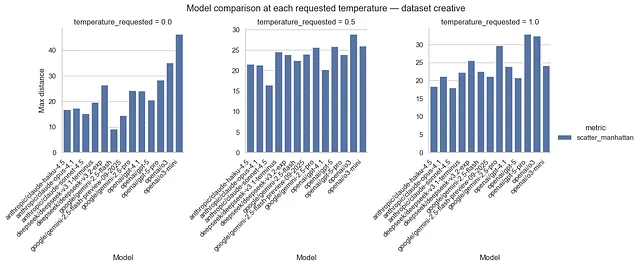
LLM创造力可以被度量吗?一个基于提示词变更的探索性实验
Agent Lightning:微软开源的框架无关 Agent 训练方案,LangChain/Aut...
2026-02-11 21:44
deephub
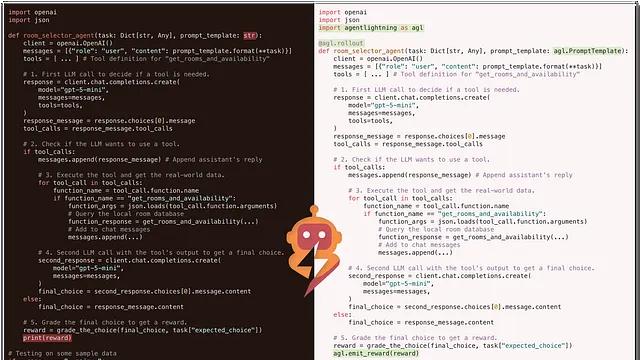
Agent Lightning:微软开源的框架无关 Agent 训练方案,LangChain/AutoGen 都能用
软件工程原则在多智能体系统中的应用:分层与解耦
2026-02-10 21:42
deephub
软件工程原则在多智能体系统中的应用:分层与解耦
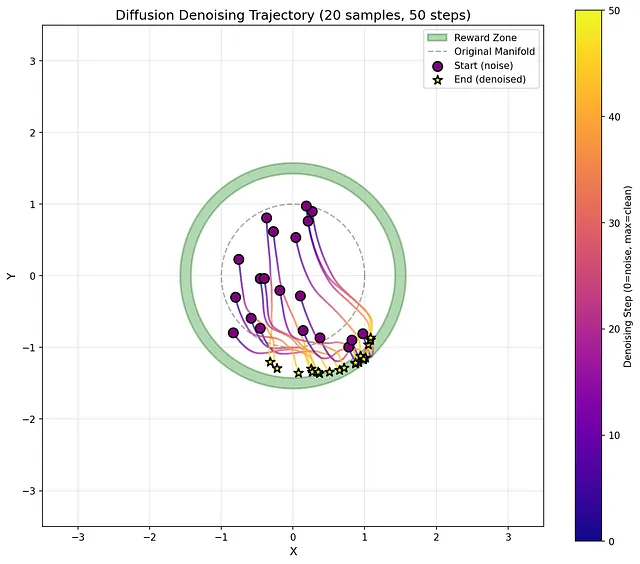
一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
2026-02-09 20:42
deephub
一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
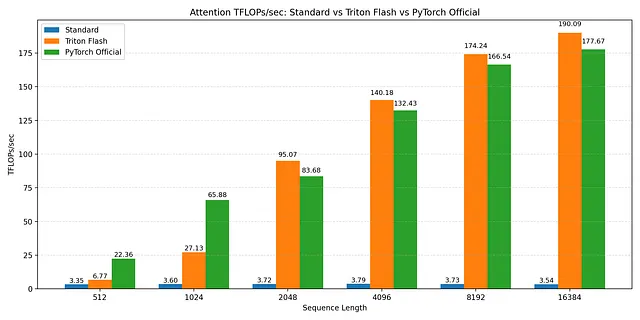
从零开始用自定义 Triton 内核编写 FlashAttention-2
2026-02-08 21:08
deephub
从零开始用自定义 Triton 内核编写 FlashAttention-2
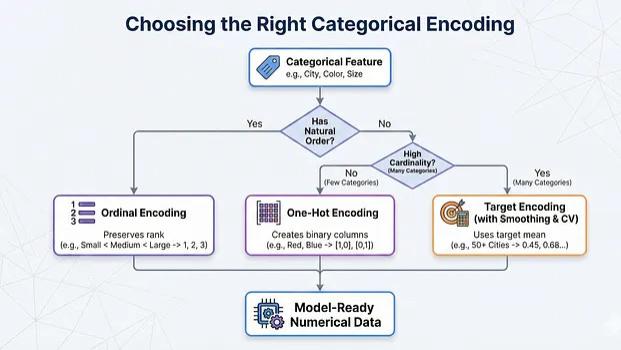
机器学习特征工程:分类变量的数值化处理方法
2026-02-07 21:29
deephub
机器学习特征工程:分类变量的数值化处理方法
LLM推理时计算技术详解:四种提升大模型推理能力的方法
2026-02-06 20:53
deephub
LLM推理时计算技术详解:四种提升大模型推理能力的方法
分类数据 EDA 实战:如何发现隐藏的层次结构
2026-02-05 22:55
deephub
分类数据 EDA 实战:如何发现隐藏的层次结构
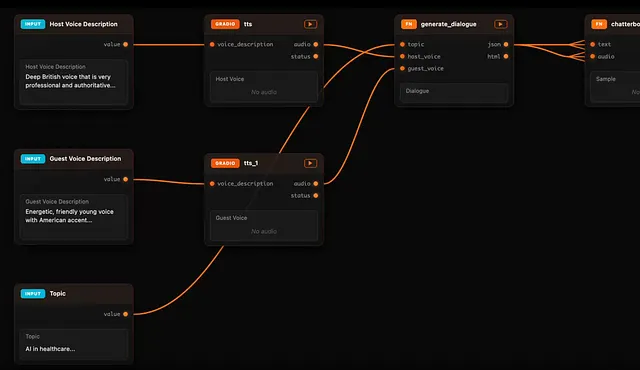
Daggr:介于 Gradio 和 ComfyUI 之间的 AI 工作流可视化方案
2026-02-04 20:50
deephub
Daggr:介于 Gradio 和 ComfyUI 之间的 AI 工作流可视化方案
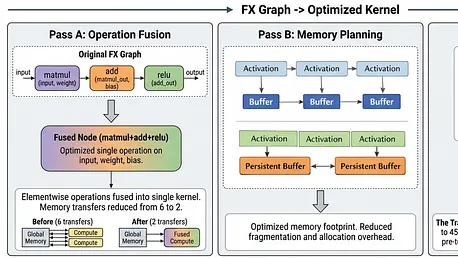
torch.compile 加速原理:kernel 融合与缓冲区复用
2026-02-03 22:20
deephub
torch.compile 加速原理:kernel 融合与缓冲区复用
第一页
作者信息
deephub
提供专业的人工智能知识,包括CV NLP 数据挖掘等
分类: 科技
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量