把一个RAG系统从Demo做到生产,中间要解决5个问题。
最初的版本就是标准版:全量文档 embedding,向量检索,LLM生成。演示没出过问题,但是翻车发生在数据留存政策的时候,因为系统召回了两段2废弃条款和一段聊"员工留存"的HR文档,然后把这三段内容揉成了一个看似完整实则全错的回答。
这不是检索的问题,也不纯粹是模型的问题。从分块方式到搜索策略,从排序逻辑到异常兜底,每一层都藏着独立的故障模式。
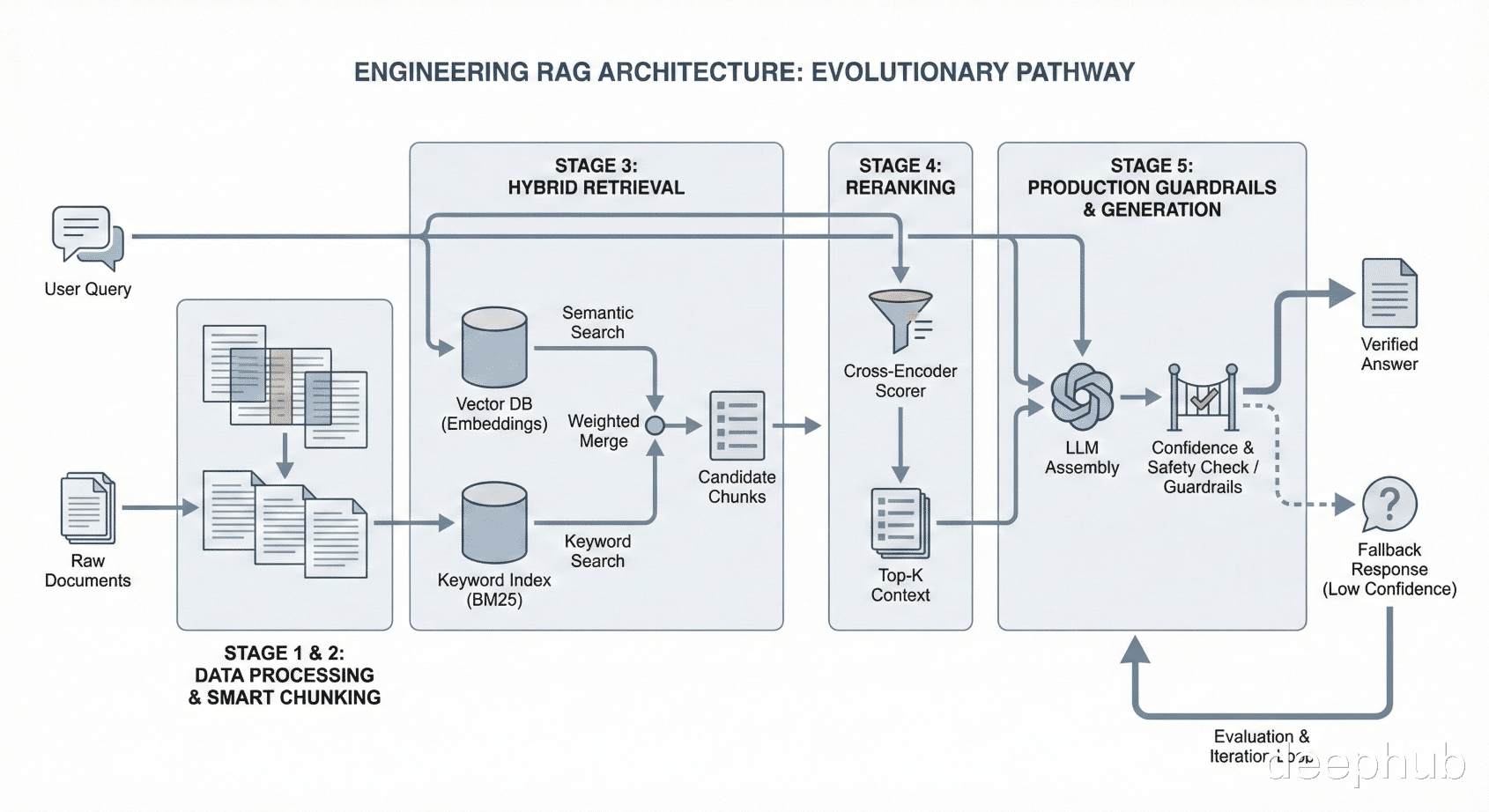
文档做 embedding,存向量,按相似度取 top-k,丢给模型生成。流程就这么简单:
from openai import OpenAI import chromadb client = OpenAI() chroma = chromadb.Client() collection = chroma.create_collection("docs") def index_document(doc_id: str, text: str): response = client.embeddings.create( model="text-embedding-3-small", input=text ) collection.add( ids=[doc_id], embeddings=[response.data[0].embedding], documents=[text] ) def naive_rag(query: str, k: int = 3) -> str: # Embed query query_embedding = client.embeddings.create( model="text-embedding-3-small", input=query ).data[0].embedding # Retrieve results = collection.query( query_embeddings=[query_embedding], n_results=k ) # Generate context = "\n\n".join(results["documents"][0]) response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": f"Answer based on this context:\n\n{context}"}, {"role": "user", "content": query} ] ) return response.choices[0].message.content
所有RAG教程教的就是这套,大多数RAG系统也停在了这一步。
问题出在哪?语义相似度不等于相关性。查"data retention policy",embedding 模型会把"employee retention programs"也拉进来,因为它看到了词汇上的重叠。两个概念八竿子打不着但向量空间里靠得很近。
还有一种情况更隐蔽:召回的 chunk 确实跟主题相关但根本没在回答你的问题。三个 chunk 都在聊数据留存可没一个提到你要查的那条具体政策。
Demo之所以看着没问题,是因为测试用的 query 本身就是你已经知道答案的。
Level 2:智能分块多数RAG故障看着像检索出了问题,实际上是分块出了问题。
按固定500 token切一刀会怎样?一份政策声明被劈成两半,问题在上半截,答案在下半截。上下文和结论被强行拆开。切出来的 chunk 单独看根本读不通。
分块尺寸这件事比想象中关键得多:100–200 tokens太碎chunk缺少语境,"90天后删除"这句话脱离了上下文根本不知道删的是什么;1000+ tokens又太长一个 chunk 里塞了好几个主题,检索的时候噪声和有效信息一把抓;300–500 tokens是个比较舒服的区间,上下文够用主题又足够聚焦。
但尺寸还不是最关键的。重叠(overlap)才是。
from langchain.text_splitter import RecursiveCharacterTextSplitter splitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=100, # This is the key separators=["\n\n", "\n", ". ", " ", ""] )
设100 token的重叠区,一个句子即使被切断了,两个相邻 chunk 里都有它的完整内容。原本卡在边界上的答案,现在从哪一侧都能检索到。
还有一个元数据的小技巧:不要只存文本本身,把来源信息也一起存进去。
def chunk_with_metadata(doc: str, source: str, doc_date: str) -> list[dict]: chunks = splitter.split_text(doc) return [ { "text": chunk, "source": source, "date": doc_date, "section": extract_section_header(chunk), } for chunk in chunks ]
这样当2019年和2024年的 chunk 同时出现在召回结果里的时候一眼就能看得出来。Prompt 里可以加"优先引用最新来源",代码里也可以在生成前直接按时间过滤。
光是这一步就解决了大约40%的检索故障。垃圾进垃圾出——chunk 质量上去了检索效果自然跟着上去。
Level 3:混合搜索假设这样一个查询:"What's our PTO policy for employees with 5+ years tenure?"
语义搜索能找到跟休假政策沾边的 chunk,概念上确实接近。关键词搜索能精确命中包含"5+ years"和"tenure"的 chunk。
单独用哪一个都不够。两路合并就可以了。
from rank_bm25 import BM25Okapi import numpy as np class HybridRetriever: def __init__(self, documents: list[str]): self.documents = documents self.embeddings = self._embed_all(documents) # BM25 for keyword matching tokenized = [doc.lower().split() for doc in documents] self.bm25 = BM25Okapi(tokenized) def _embed_all(self, docs: list[str]) -> list[list[float]]: response = client.embeddings.create( model="text-embedding-3-small", input=docs ) return [d.embedding for d in response.data] def search(self, query: str, k: int = 5, alpha: float = 0.5) -> list[str]: # Semantic scores (normalized) q_emb = client.embeddings.create( model="text-embedding-3-small", input=query ).data[0].embedding sem_scores = np.dot(self.embeddings, q_emb) sem_scores = (sem_scores - sem_scores.min()) / (sem_scores.max() - sem_scores.min() + 1e-8) # BM25 scores (normalized) bm25_scores = np.array(self.bm25.get_scores(query.lower().split())) if bm25_scores.max() > 0: bm25_scores = bm25_scores / bm25_scores.max() # Combine: alpha controls semantic vs keyword weight combined = alpha * sem_scores + (1 - alpha) * bm25_scores top_k = np.argsort(combined)[::-1][:k] return [self.documents[i] for i in top_k]
alpha 的调法:如果语料里领域术语多(法律、医学、公司内部缩写),alpha 调低一些让 BM25 主导;如果用户提的是自然语言问题,alpha 调高让语义检索权重大一些。初始值设0.5,然后看哪些 query 挂了再微调。
BM25是很老的技术了,也没人再专门为它写博客了。但它能兜住纯向量搜索漏掉的那些 case,尤其是用户输入的恰好是文档里的原始表述时。
Level 4:Reranking检索回来5个 chunk,跟主题都沾边。但哪些真正在回答问题?
Embedding 相似度是单独算的,每份文档独立跟 query 打分。Reranker 不一样——它把 query 和文档放在一起看,问的是:"这份文档是不是在回答这个问题?"
from sentence_transformers import CrossEncoder class RerankedRetriever: def __init__(self, documents: list[str]): self.hybrid = HybridRetriever(documents) self.reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2") def search(self, query: str, k: int = 3) -> list[str]: # Get 20 candidates (cheap, fast) candidates = self.hybrid.search(query, k=20) # Rerank with cross-encoder (expensive, accurate) pairs = [(query, doc) for doc in candidates] scores = self.reranker.predict(pairs) # Return top k after reranking reranked = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True) return [doc for doc, _ in reranked[:k]]
Cross-encoder 没办法预先算好文档 embedding,必须 query 和文档一起输入。所以拿它做全量检索不现实——一万篇文档逐条打分太慢了。但从20个候选里精选3个?这个开销完全可以接受。
加入 reranking 之后"正确 chunk 出现在前3"的命中率从68%提到了89%。其实相关的 chunk 一直被检索到了,只是排名不够靠前。
不过有一点要清楚:reranking 救不了烂检索。如果正确的 chunk 根本不在那20个候选里,reranker 也变不出来。先把 Level 2 和 Level 3 做扎实。
Level 5:生产级RAG前面几个级别都在提升检索质量。生产级RAG要处理的是另一件事:检索已经尽力了,但还是失败了,怎么办?
因为它一定会失败,用户会问文档里根本没覆盖的问题。分块策略会漏掉某个关键段落。或者问题本身就很模糊,召回的几个 chunk 互相矛盾。
真正该问的不是"怎么杜绝检索失败",而是"检索失败的时候,系统该怎么表现"。
护栏上下文不够的时候,别让LLM自己编。
Air Canada 在这件事上付出了代价——他们输了一场官司,原因是聊天机器人编造了一条根本不存在的退款政策
def guarded_rag(query: str, retriever, min_score: float = 0.6) -> str: results = retriever.search_with_scores(query, k=3) # Check: Do we have ANY confident results? top_score = results[0][1] if results else 0 if top_score < min_score: return ( "I don't have enough information to answer that confidently. " "Could you rephrase, or is there a specific document I should look at?" ) # Check: Are sources from different time periods? dates = [r["date"] for r, _ in results] date_warning = "" if len(set(dates)) > 1: newest = max(dates) if any(d < newest for d in dates): date_warning = "\n\n[Note: Some sources are older. The most recent policy takes precedence.]" # Generate with explicit grounding instruction context = "\n\n---\n\n".join([r["text"] for r, _ in results]) response = client.chat.completions.create( model="gpt-4", messages=[ { "role": "system", "content": f"""Answer based ONLY on the provided context. If the context doesn't contain enough information, say so explicitly. Never infer or make up information not directly stated. Context: {context}""" }, {"role": "user", "content": query} ] ) return response.choices[0].message.content + date_warning
评估没法度量的东西就没法改进。先建一组测试 query,每条都带上已知的正确答案:
test_cases = [ { "query": "What's our data retention policy for customer records?", "must_retrieve": ["data-retention-policy-2024.md"], "answer_must_contain": ["7 years", "deletion request"], "answer_must_not_contain": ["2019", "employee retention"] }, # ... 50+ more cases covering your actual use cases ]
每次改动跑一遍。追踪检索精度(拿到正确文档了吗)和答案准确率(关键事实对了吗)。哪个指标掉了,马上能定位到是哪一步出了问题。
做到这一步仍然会有边缘 case。用户的表述方式超出预期,文档里藏着你不知道的自相矛盾。
边缘 case 漏不了。关键是让系统在拿不准的时候老实说"不知道",而不是胡编一个答案。
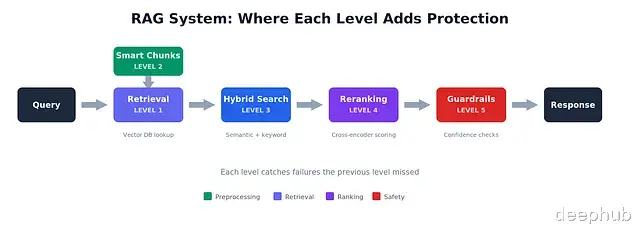
不是所有场景都需要做到 Level 5。
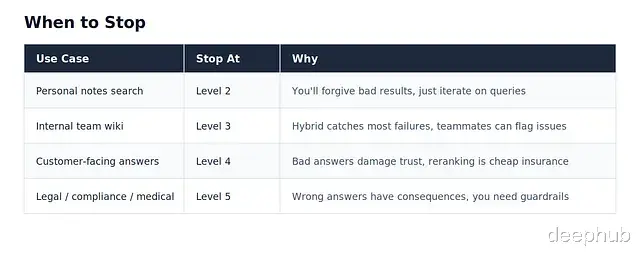
判断该不该升级,看用户反馈就行:
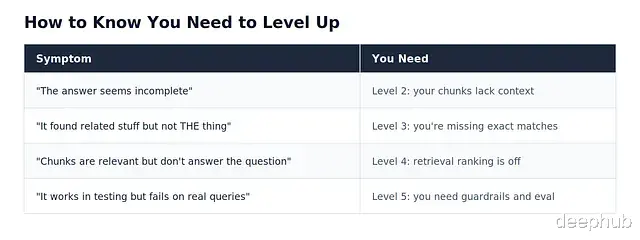
用户在抱怨什么RAG就坏在哪里。
从 Level 1 开始。记录并监控系统在哪翻车,搞清楚原因之后再往上走。
这才是构建一个真正能用的RAG系统的路径。
https://avoid.overfit.cn/post/93d89f1be12b421dbbb761198960bc76
by Paolo Perrone