CUDA真是NVIDIA绝对牢不可破的生态吗?未来不会再有对手了吗?所有的科学计算都只能使用n卡?
CUDA 作为 NVIDIA 打造的计算生态核心,凭借十余年的积累构建了难以撼动的行业优势,成为科学计算、AI 训练等高性能场景的主流选择。但这并非 “绝对牢不可破” 的垄断壁垒,随着市场需求、政策导向与技术进步的多重推动,替代方案加速崛起,科学计算 “唯 N 卡独尊” 的格局正逐步被打破,未来将走向多元化共存。

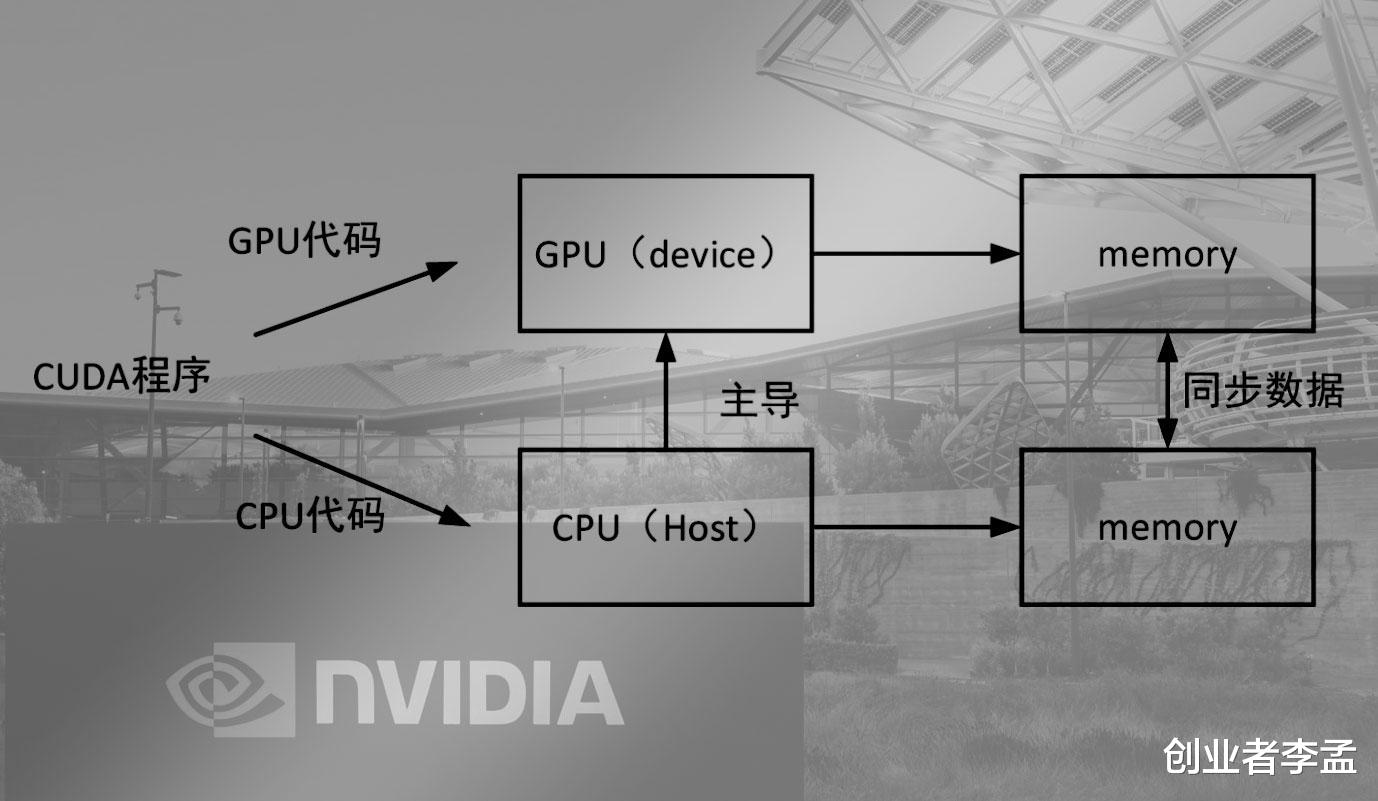
CUDA 的生态壁垒核心源于三层闭环优势
其一、工具链的完整性无可短期复制。CUDA 不仅是 CPU 与 GPU 的 “翻译官”,更配套了 cuDNN、cuBLAS 等一系列深度优化的工具库,覆盖深度学习、线性代数、图形渲染等核心场景,这些库是 NVIDIA 投入海量资源打磨的成果,实现了硬件性能的极致释放。
其二、开发者的沉没成本形成强绑定。十几年来,全球科研人员与企业积累了海量 CUDA 专属代码,从实验室脚本到工业级仿真软件,迁移这些资产需要巨大的时间与人力成本,导致用户倾向于持续选择 N 卡。
其三、软硬件深度绑定构建差异化优势。NVIDIA 每代 GPU 的新硬件特性(如 Tensor Core、FP8 精度)都会第一时间通过 CUDA 完成原生优化,形成 “硬件迭代 - 软件适配 - 性能提升” 的正向循环,让竞争对手难以通过单纯的硬件参数追赶。

然而CUDA 的垄断地位正面临三大方向的有力挑战
首先是国产 GPU 的原生生态突围。摩尔线程、壁仞科技等国产厂商并未死磕 CUDA 原生兼容,而是采用 “兼容层过渡 + 原生生态深耕” 的策略:通过软件兼容层降低老 CUDA 程序的迁移成本,同时重点打造 MUSA、BMRuntime 等专属架构,搭配政策驱动下的国产化替代需求,国内科研机构、国企等场景正逐步适配国产 GPU,积累原生代码资产与用户基础。
其次,跨平台标准的统一化削弱了 CUDA 的 “独家语言优势”。SYCL、oneAPI 等标准致力于实现 “一套代码、多硬件兼容”,让开发者无需绑定特定厂商,就像网页兼容不同浏览器一样,打破了 CUDA 的专属壁垒;OpenCL 等老牌标准也在 AI 框架的支持下持续优化,性能差距不断缩小。
最后,AI 框架的多后端支持从源头松绑。PyTorch、TensorFlow 等主流框架已逐步完善对 MUSA、ROCm 等非 CUDA 后端的支持,开发者无需编写 CUDA 专属代码,仅通过框架原生接口即可适配不同品牌 GPU,让用户拥有了更多选择权。


在科学计算领域,当前 “大多用 N 卡” 的现状正发生渐变
复杂高性能场景(如大模型训练、高精度核聚变仿真、电影特效渲染)仍高度依赖 CUDA 的优化与稳定性,N 卡仍是首选;但中低强度场景(如高校基础数据分析、小型 AI 推理、普通数值计算)中,国产卡、AMD 卡已能满足需求,性能虽非顶尖但足以支撑业务。
未来,随着国产 GPU 性能提升、跨平台标准成熟,中型 AI 训练、行业级仿真等场景将出现 “N 卡为主、多卡补充” 的格局,超算中心也会混合部署不同品牌 GPU,避免单一依赖。
所以我们短期来看,3-5 年内 CUDA 生态仍将保持领先,N 卡在高性能计算中依旧占据优势;但长期而言,5-10 年后生态多元化将成为主流。技术垄断终究抵不过 “自主可控” 的市场需求、政策驱动的国产化浪潮与跨平台技术的进步,CUDA 将从 “唯一标准” 转变为 “标准之一”。科学计算不会永远绑定 N 卡,一个多品牌共存、用户自主选择的新时代,正在加速到来。对此大家是怎么看的,欢迎关注我“创业者李孟”和我一起交流!