就在全球AI巨头OpenAI发布GPT-5.1、谷歌推出Gemini 3系列之际,国内AI独角兽DeepSeek悄然放出了“王炸”——DeepSeek-Math-V2。这个拥有6850亿参数的数学专用模型,在国际数学奥林匹克竞赛(IMO 2025)中达到了金牌水平,成为首个达到此成就的开源模型!
数学界的“地狱难度”测试成绩惊艳在被称为“数学界炼狱”的普特南数学竞赛中,DeepSeek-Math-V2取得了118分(满分120分)的近乎满分成绩,远超人类选手约90分的历史最高分记录。这个成绩意味着什么?相当于一个AI在大学生最高水平的数学竞赛中,几乎把所有题目都做对了!
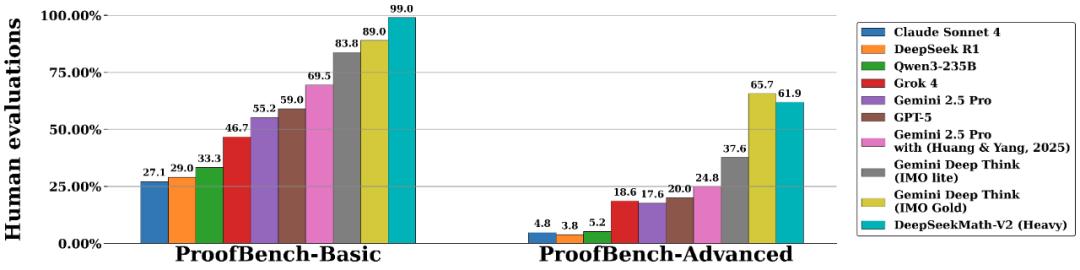
更令人振奋的是,在IMO-ProofBench基准测试的基础集上,Math-V2得分接近99%,大幅领先谷歌旗下Gemini DeepThink的89%。即便在难度更高的进阶集上,作为开源模型的Math-V2也达到了闭源商用模型顶尖水平的61.9%。

这个发布的时间点颇为耐人寻味。就在模型开源前不到24小时,前OpenAI首席科学家Ilya Sutskever还在质疑当前AI模型只是“死记硬背”的做题机器。而DeepSeek Math-V2的发布,仿佛是一次跨越时空的回应。
传统的AI训练往往陷入“结果导向”陷阱——只要答案正确就给奖励。这导致AI产生投机行为,为了获取奖励而猜测答案,即便中间逻辑混乱。DeepSeek一针见血地指出:正确的答案并不保证正确的推理!
独创“元验证”机制,让AI学会自我反省为了解决这个问题,DeepSeek团队设计了一套创新的“元验证”机制,可以理解为“学生-老师-校长”三层监督体系:
AI“学生”负责解题,AI“老师”负责批改,而更高层级的AI“校长”则审查判卷的合理性。如果“老师”出现误判,“校长”会进行纠正。这种层层嵌套的监督体系,直接将评分系统的置信度从0.85提升至0.96。
更厉害的是,Math-V2展现出了类似人类“三省吾身”的自我反思能力。在处理高难度定理证明时,模型会像严谨的数学家一样,在推理过程中进行停顿和自省。一旦发现逻辑漏洞,就自主推翻重写,直到逻辑链条无懈可击。
DeepSeek Math-V2的发布在海外开发者社区引发强烈反响,被舆论称为“鲸鱼回归”。市场分析人士认为,DeepSeek以明显优势击败谷歌获奖模型,打破了顶级推理模型长期被闭源巨头垄断的局面。
有资深算法工程师表示:“DeepSeek验证了‘自验证推理路径’的可行性。数学推理能力是代码生成、科学计算等任务的基石。这一技术极有可能迁移至编程模型,届时将对现有代码辅助工具市场产生巨大冲击。”
技术突破背后的深远意义当前,全球AI大模型正处在从“文本生成”向“逻辑推理”进化的关键窗口期。DeepSeek此次“亮剑”,不仅证明了国产模型在高端算法领域的竞争力,也为开源社区提供了一条清晰的技术演进路线——通过构建严谨的验证机制,而非单纯堆砌算力,来实现机器智能的质变。
目前,DeepSeek新模型的代码与权重已在Hugging Face及GitHub平台完全开源。这意味着全球的开发者、研究人员都可以免费使用这个达到国际数学奥赛金牌水平的AI模型,这将极大推动整个AI行业在推理能力方面的发展。

从做题机器到严谨数学家,DeepSeek Math-V2的突破告诉我们:通往超级智能的路径并非只有算力的堆叠,更需要懂得“回头看”的智慧。这或许正是AI从工具走向智能伙伴的关键一步!