最近的美国AI圈,非常热闹。
9月22日,英伟达宣布向OpenAI投资最高1000亿美元,以建设用于训练和运行下一代大规模 AI 模型的数据中心。OpenAl再将这笔资金用于采购英伟达芯片系统,同时英伟达将获得 OpenAI 的非控股股权作为回报。
10月6日,OpenAI与AMD达成AI芯片供应协议,OpenAl将部署价值数十亿美元的AMD芯片,绑定了与算力部署相关的10%的股权投资。
最近一段时间,OpenAI与英伟达、AMD、甲骨文等巨头签署了总额近1万亿美元的算力协议。这个数字远超其营收。OpenAl还将向云服务商CoreWeave支付高达224亿美元。
与此同时,马斯克的xAI采用一种与芯片采购直接“挂钩”的创新融资结构,推进一轮高达200亿美元的融资。
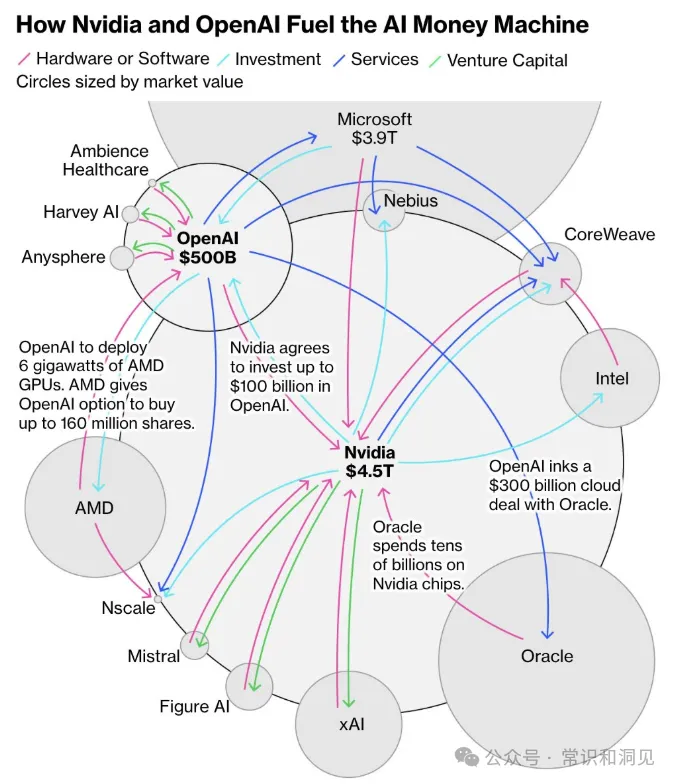
在这些协议之下,OpenAl、英伟达、AMD、甲骨文、微软、CoreWeave等巨头通过股权、债务及长期算力购买合约,形成了庞大的绑定网络。资金在这个网络中的芯片、云、数据中心及能源企业之间循环流转。
那么,为什么会出现这个局面?其实,某种程度上,这不是因为确定性,而是为了更确定的,应对不确定性。

Part 1
人工智能史上的重要人物图灵奖得主、Meta首席AI科学家、纽约大学教授杨立昆对大模型的未来并不看好。美国国家工程院院士,被称为AI教母的李飞飞也持有类似看法。
他们的观点是类似的,即现在的大型语言模型(LLM)主要基于文本数据训练,擅长反刍和检索知识,但缺乏对物理世界的理解和推理能力,无法进行真正的推理,无法发明新的东西或提出自己的科学发现,离接近人类水平的智能还非常遥远。
麻省理工学院、芝加哥大学和哈佛大学联合发表的研究论文,也提出一个叫“波将金式理解”的概念,直接质疑了现在靠纯LLM来实现通用人工智能(AGI)的主流思路。
强化学习之父、2024年图灵奖得主、“算力至上”的旗手理查德·萨顿,也正在不断向科技巨头们发出警告:“大语言模型是错误的起点,是条死胡同。”在9月底的一次深度访谈中,他称:
“单纯堆砌算力的大模型,可能永远无法实现通用智能。”
其实,萨顿并未背叛自己“算力至上”的观点,毕竟,当年他那篇影响深远的短文《苦涩的教训》里最核心的前提是:只有那些直接从经验中获得的算法,才具有无限扩展的潜力。
《黑天鹅》《反脆弱》的作者塔勒布,也认为LLM依赖于概率和现有数据,它们被限制在“最有可能”的领域,而不是“最具创新性”的领域。这限制了其提供革命性见解的能力。
而且,大模型还可能陷入“自我舔舐的棒棒糖”这样一个递归陷阱。随着LLM生成越来越多的内容,充斥网络,未来,用来训练LLM的数据,就是其先前生成的数据。这会逐渐稀释网络内容的多样性和原创性。

Part 2
这些都意味着,技术前路并不确定。其实,美国的市场机制一直很擅长应对这种情况,即各种技术试错大战,比如,浏览器大战、显卡芯片大战,甚至cpu大战。这些方式,这似乎才是目前最佳的试错方式。
浏览器首次大战,始于1995年微软在windows中绑定IE浏览器,打击网景,引发反垄断诉讼。后以1998年网景被AOL收购结束。第二次浏览器大战发生在2004年,Firefox、Chrome、Safari和Opera等浏览器逐步侵蚀IE市场主导地位。Chrome凭借沙盒架构及扩展生态实现反超。
更残酷的是显卡芯片大战。上世纪90年代,Nvidia创始人黄仁勋在创办公司时曾经给一位Bay Area公司的分析师打电话,想听听对自己准备在图形芯片领域创业的建议。这位叫乔恩的分析师告诉他:“这个市场还没起步且已经乱成一团了,现在已经有将近30家公司,你最好别干这个。”
早在大多数中国人还不知道电脑为何物的1990年,就有20家厂商宣称开发个人电脑用3D显卡芯片。1996年更急速膨胀到70家。待到90年代末,呈现出群雄逐鹿中原的局面。
很多经历过那个时代的人现在应该还记得一些品牌的名字:ATI、Matrox、Permedia、S3、3dfx、Trident、NEC、SiS。到了2000年,经过激烈的竞争,显卡芯片厂家快速缩减至12 家。但在激烈的试错中,跑出来了AMD和nvidia,并最终成就了AI时代。

相反,不经过激烈的试错,全力下注某个技术路线,代价是很大的。
上世纪80年代初,日本政府制定了一个野心勃勃的十年规划,打造第五代计算机,打算在IT领域一举超越美国。规划一推出,就震惊欧美,一些美国人甚至认为,这是日本人在计算机领域的“珍珠港事件”!
当时的日本,随着战后经济爆发式发展,在消费类电子和汽车工业已经是世界领先。在半导体领域,通过组织半导体协会,把产业整合在一起,在很短的时间内就全面赶超了美国公司,占据了70%的存储半导体市场。Intel公司转向微型处理器,也是因为这个原因。
这时的日本信心爆棚,觉得他们已经进入“无人区”,必须创新,实施弯道超车。日本的目标是,抛弃冯诺依曼架构,采用新的并行架构,新的编程语言,处理自然语言、图像。显然,日本的技术方向其实是正确的,如今的GPU也正是并行结构,日本当年的目标,也带有AI的影子了。
但日本失败了,而美国在PC的带动下,多媒体走入千家万户,摩尔定律带动了计算机、互联网的发展。
那么,为什么美国现在的AI巨头,不采取这种方式去应对AI技术路线的不确定性,而是抱团大力下注大模型呢?

Part 3
在我看来,有三个原因。
首先,大模型,规模法则(Scaling Law)非常有效,大模型短期的前途是明显的。
当增加AI模型中的参数数量,并增加训练数据和算力时,模型的性能并不是线性提升的,而是随着模型规模(参数数量)、训练数据集大小及计算资源的增加,而呈显著提高。这种规律被称为规模法则(Scaling Law)。这被业界认为是大模型预训练第一性原理。
而且,当模型或数据达到一定规模时,我们可能会看到性能非线性的突然跃升。大模型会突然能理解隐喻、讽刺等复杂语言现象,表现出人类般的常识推理能力,并可能在没有专门训练的情况下,突然能够执行多种不同类型的任务。这就是涌现能力。
所以,即便最终不能达到“真正的通用人工智能”目标,但在实用性上,目前大模型的前景仍然是确定的。为了追求性能的提升,特别是涌现能力,所以,各方都砸巨资,追求更大的规模。
追求涌现能力所需的资金量非常大。根据知名金融机构摩根士丹利的预测,在接下来的五年里,全球用于建设和维护支持人工智能的数据中心的总支出,将高达约三万亿美元。
微软今年Q1宣布未来三年AI资本开支提升至1200亿美金,谷歌紧随其后将数据中心建设预算上调40%,甲骨文更是喊出“五年内算力规模翻20倍”的目标。比起公司自己融资,产业链的相互投资可以刺激出资本市场更大的预期,带来更多潜在资金。
更重要的是,这是一场不能三心二意的战争,没人想看到其他人偏离现有的技术路线。所以,上游的nvidia,中游的云计算,下游的ai厂商,都需要相互交出投名状。
交叉投资,不仅是整合产业链,稳定芯片来源,也有绑定同行,大家一起下注的作用。毕竟,技术路线是人为的,当大家都在一条船上,这条技术路线的胜算就更大。
即便大模型不是真正的答案,由此可能形成的路径依赖,市场优势,可以帮助这一轮大模型的赢家,获得下一轮“真正的通用人工智能”的先机。
所以,巨大的资金量,意愿的稳定性,都迫使头部公司,抱团取暖,相互绑定。

Part 4
还有一个非常重要,但却被忽略,与中国相关的原因是,领先者模仿追赶者机制。
1986年的“美洲杯帆船赛”中,美国队果然一路领先。在离终点还有四海里的时候,海上的风转向了。
风向转了,有两种情况。一种情况是旋风,过会儿就会恢复原来的风向。这种情况下,帆船就不需要调帆。因为调帆适应风向,费时间,会耽误船的速度,不如等待风向转会。另一种情况阵风,风向转了不再变了,就必须调帆,获得最大动力。
所以,帆船比赛,不可能风向一变就跟着调,需要判断。老船长说这风是阵风,船员就调帆。但老船长判断错了,风向又变回来了。这意味着美国队还得调回来。调两次帆,船原地不动,而澳大利亚队没有调帆,就超过了美国队得了冠军。
后来,媒体开始批评老船长决策错误。老船长不服,说判断风向靠运气,不怪我。不过,有博弈专家出来反驳说:不,和天气无关,就怪你。
专家给出了一个方案:当领先时,海上风发生转向时,不要看天,要回头看对手。对手调我们就调,对手不调,我们就不调。如果对手判断对了,他能从风中获得最大动力,我们也能。我们领先三海里。如果对手判断错了,他动不了了,我们也动不了,但仍然领先三海里。无论对错,都可以保持领先。
如果不跟追赶者采取一致的措施,有两种情况。
第一种,他的判断对了,从风中获得最大速度。你的判断错了,停下来。他赶上你。这也是比赛中实际发生的情况。
另一种,他判断错了,你判断对了,他停下来,你领先得更多。但是,这种领先对于获得冠军,保持优势,是没有意义的。不值得拿失去冠军去冒险。这就是著名的“领先者模仿追赶者”策略:在帆船比赛中,只要你是领先者,就不必太在意方向。你只需要观察追赶者的动作,他调帆你就调,他不调你就不调。因为无论你是前进还是原地打转,大家一起“都对或都错”,你都领先对手。

通常的认知是,追赶者要模仿领先者。这是从追赶者的视角出发。但对于领先者而言,有足够的领先优势,就反而应该模仿追赶者。无论第二名采用何种策略,第一名只需跟随第二名保持一致,就能稳住自己的地位。
所以,一定程度上,美国AI行业也在模仿中国的产业链整合的模式,OpenAI旨在通过相互投资,整合AI全产业链。
目前,中国在追赶方面,已经非常有优势,有了一套自己成熟的方法论。
中国在“从1到100”的产业化扩张方面,已展现出全球瞩目的能力。这指的是将一项已被验证的技术或原型,通过整合产业链、政府促进投资等方式,促进大规模制造和持续优化,进而发展为具有全球竞争力的高效率成熟产业。
在新能源车、光伏方面,中国通过这种模式,已经占据了全球优势地位。目前,在大模型领域,中国也在努力追赶。
因此,具有领先地位的美国ai企业,最佳策略是模仿中国的方式,自己整合产业链,避免产业外溢,进而避免中国通过整合产业链的方式超车。
比如,近期美国政府以89亿美元资金、软银集团20亿美元资金投资Intel,收购英特尔10%的股份后,NVIDIA也以每股23.28美元的价格认购50亿美元Intel普通股。
这对于在CPU市场的全产品线中连年受挫、自身工艺水平落后的英特尔来说,这无疑是雪中送炭。对于NVIDIA来讲,在GPU领域无人能敌,但CPU方面与Intel合作,可以弥补自己CPU方面的短板,并整合成在各领域具有优势的SoC。
显然,当下的很多美国人并不愿意看到nvidia借现在的优势,向x86发起进攻,而是愿意看到一种整合协同的态势。
除了在人工智能领域,我们也可以看到各国政府在产业政策中,正在发挥越来越大的作用。某种程度上,这都是“模仿追赶者”的策略。

ai
Part 5
对此,我们应该有清醒的认识。
首先,领先者的模仿,并非一定因为追赶者策略是对的。而是为了“都对、都错”,保持优势。那么,我们就不能用其他国家政府的政策,来论证目前一些产业政策的正确性,而应该客观看到其带来的内卷等后果。
更重要的是,领先者,模仿后来者,是为了消除不确定性。但挑战者要想打破竞争格局,则需要进行颠覆性改变。追赶者需要差异,因为只有差异化搅局,才有不确定性,自己才有机会。如果追赶者,看到领先者在模仿自己,维持自己的策略,反而会因为丧失不确定性,导致差距的固化。所以,超大市场规模的优势,并不仅仅在于整合,而在于创新。

END
刘 远 举

央视网、第一财经、光明日报、腾讯大家、南方周末、新京报、南方都市报、FT中文网、澎湃等特约作家,多家智库研究员。
关注时政、财经、科技话题,以深度、专业、理性的态度,去掘现象背后的事实。
第34届中国经济新闻奖,评论一等奖
第28届北京新闻奖一等奖
腾讯大家年度作家奖
新浪最有价值专栏作家奖
红辣椒评论年度佳作奖
中国科技自媒体50人