转载自:minimax稀宇科技
随着minimaxm2.5的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于agentrl系统的一些思考。
在大规模、复杂的真实世界场景中跑rl时,始终面临一个核心难题:如何在系统吞吐量、训练稳定性与agent灵活性这三者之间取得平衡。为了解决这个问题,我们设计了一个异步的原生agentrl系统——forge。在forge中,我们通过实现标准化的agent-llm交互协议,支持了对任意agent脚手架进行训练,并且通过极致的工程优化和稳定的算法与奖励设计,实现了超大规模的强化学习。
在面对数十万个真实的agent脚手架和环境以及200k的上下文长度时,我们的rl系统做到了每天百万级样本量的吞吐,并实现持续稳定的reward上涨和真实的模型能力提升,并最终造就了minimaxm2.5模型的性能突破。
问题建模
在深入探讨架构设计之前,我们首先将agent强化学习系统的优化目标形式化为“最大化有效训练收益(j)”:

其中,throughput是指每秒处理的原始token数量,其主要受rl系统中的四部分控制:rollout、training、dataprocessing和i/o。sampleefficiency则是指每个样本带来的平均性能提升,由数据分布、数据质量、算法效率以及offpolicy程度决定。而稳定性和收敛性则能够基于训练过程中监测指标来判定。
要实现(j)的最大化,我们需要克服以下三类挑战:
当前常见的rl框架和范式对agent的复杂度限制很大,主要体现在:
agent自由度受限:将agent视为白盒就要求在agent和rlframework之间共享和传递状态。这种设计难以对复杂的agent架构(如动态上下文管理、multi-agentrl等)进行建模,导致模型能力无法在复杂的黑盒agent上有效泛化。
token一致性问题:现有的tito(token-in-token-out)模式迫使agent与底层的tokenizer逻辑深度耦合。在复杂的上下文管理机制下,要想维持agent和rl之间的严格一致性,其工程成本是非常大的。
rollout的完成时间存在极大的方差——短则几秒长则数小时。这带来了一个异步调度问题:
训推异步调度逻辑:跑过异步rl的同学都知道,在mfu和rl算法稳定性之间权衡是非常复杂的。严格的fifo(firstinfirstout)/同步调度会被于长尾样本block;而greedy/fffo(firstfinishfirstout)虽然最大化了吞吐量,却带来了不可控的distributionshift,极易导致rl中途崩掉。
前缀冗余:在多轮agent请求和group-level的rollout中,tokenizer的encode-decode不一致性和上下文管理机制,会导致请求间共享了大量的前缀,这种冗余在训练期间造成了巨大的计算浪费。
稀疏奖励问题:复杂的agent任务的trajectory通常包括长达数千步,使得基于稀疏奖励的creditassignment在数学上非常不稳定。这种稀疏性导致回报计算中的信噪比极低,引起高梯度方差,破坏了大规模模型训练的稳定性。
longcot的负面影响:在r1出来之后大家的rl都很关注responselength的增长。但在真实的agent场景中,用户其实对执行时间非常关注,如果不加以限制可能会导致训出来的模型虽然刷榜很强,但用户体验很差。
系统架构与agentrl范式
rl系统设计
为了实现真正可扩展的架构,我们不再局限于具体的agent,而是转向了通用的抽象层设计,将agent的执行逻辑与底层的训推引擎彻底解耦。我们的rl系统由3个核心模块组成:
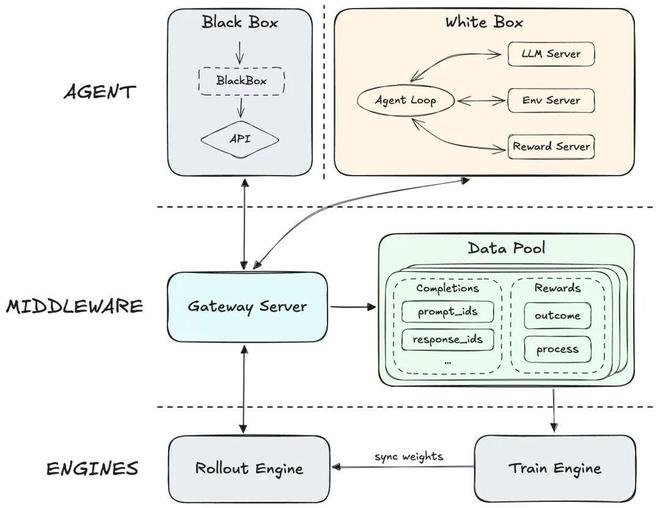
1.agent:该层抽象了通用agent(涵盖白盒和黑盒架构)及其运行环境。它负责协调环境交互,使agent成为一个纯粹的trajectoryproducer。通过将环境交互与llmgeneration解耦,agent可以专注于核心业务逻辑(如contextmanagement和复杂的环境交互等),而无需关心底层的训练和推理细节。
2.中间件抽象层:作为桥梁,该层在物理上将agent侧与训练/推理引擎隔离。
gatewayserver:充当标准化通信网关,处理agent与llm之间的交互请求。通过通用标准协议,它有效地将底层模型的复杂性与agent的高层行为逻辑隔离开来。
datapool:作为分布式数据存储,异步收集trajectory和processsignal。它充当生成和训练解耦的缓冲区,允许灵活的数据处理和批处理策略。
3.训练与推理引擎:
rolloutengine:专用于高吞吐量token生成,响应agent的生成请求。
trainengine:通过scheduler从datapool中fetch数据,更新agentmodel,并与采样引擎保持同步,确保agent使用最新的策略分布进行探索。
我们在离线评估中发现,不同agent脚手架会导致显著的性能偏差。借助该模块化设计,我们在无需修改agent内部代码的情况下,使用大量的agent框架进行了训练。这种“引擎与agent完全解耦”的架构确保了模型能在各类环境中泛化,目前我们已集成了数百种框架和数千种不同的工具调用格式。
对于白盒agent,我们可以通过充分的脚手架设计和增广,以直接观测和优化模型在特定类型agent上的表现。在m2.5中,我们特别优化了过去模型在带上下文管理的长程任务(如deepsearch)中出现的一些问题:
上下文场景性能退化:随着交互轮次增加,中间推理和冗余观察的积累会产生“注意力稀释”。这种噪声会导致模型在绝对上下文窗口内对关键信息失去焦点。
训推不一致:虽然上下文管理可以延长交互周期,提升agent在长上下文场景的表现,但仅在推理时使用会由于偏离rl训练的数据分布,迫使模型在推理时被迫接受上下文变迁,处理不常见的长下文,从而影响模型表现。
为了解决这些问题,我们将上下文管理(contextmanagement,cm)机制直接整合到rl交互循环中,将其视为驱动状态转换的功能性动作:
cm驱动的状态转换:我们将cm建模为agentaction,而上下文变迁则蕴含在环境的dynamics中。状态从s(t)到s(t+1)的转换隐式包含了上下文切换的逻辑,将上下文适应包含在了模型的训练目标中。
自适应推理模式:通过在此框架内优化策略π(θ),模型学会了内化分布偏移,涌现出优先关注state-criticaltoken的鲁棒推理模式。
感知上下文管理策略:在该策略下,模型在rl生成过程中就需要学会预见可能的上下文管理和改变,模型通过主动保留与目标任务相关的信息和减少无关上下文信息,大幅提升了在context-managementagent下的性能。
许多用户的真正在用的agent实际上是闭源的,我们完全无法感知内部的agentloop逻辑。为了确保模型在不透明架构上也能对脚手架针对性优化,我们采用了以下方案:
非侵入式集成:forge不感知agent内部的实现细节,内部只需要将请求打到rl服务的gateway,框架内部即可进行数据收集和训练,因此在实际rl训练时可以兼容任意上下文操作(如记忆压缩、历史重写),任意内部的agentloop(例如deepthink、multi-agent等等)。
多框架泛化:通过将训练循环与agent内部状态解耦,minimaxm2.5广泛适配大量黑盒agent——无论是以沙盒+mcp环境为主的代码agent(例如我们将opencodeagent直接视为一个黑盒agent来训练),还是使用激进上下文缩减策略的agent(如truncatebc)。实验表明,该方法在完全不透明的黑盒系统上依然能带来稳定的提升。
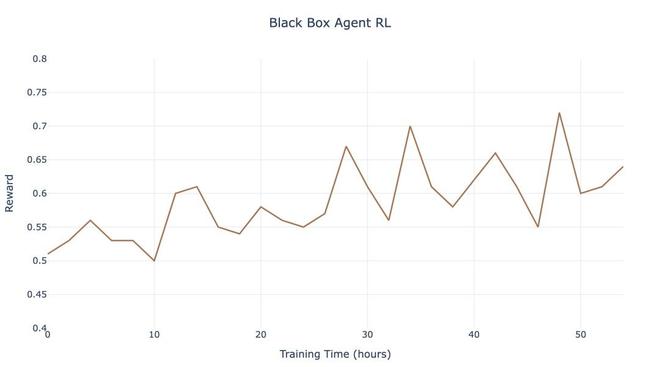
工程优化
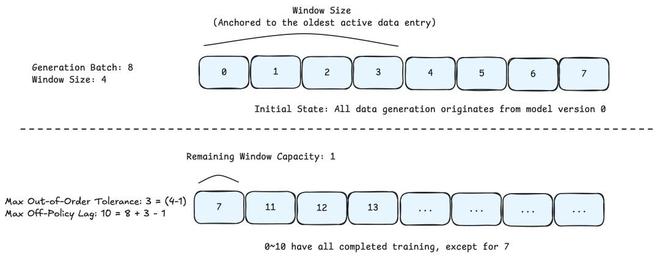
为了解决吞吐量与数据分布一致性之间的冲突,我们提出了windowedfifo调度策略。该策略介于fifo和greedy之间,即可以保证系统的吞吐,也控制了样本的off-policyness。
假设当前达到了最大的生成并发量(如n=8192),生成队列为q,当前头部位于索引h。训练调度器受限于一个大小为w(如w=4096)的可见窗口:
受限可见性:调度器只能从范围内获取已完成的轨迹。
局部贪婪(窗口内):在活动窗口内,调度器可立即提取任何已完成轨迹,避免了队头阻塞(hol),快速任务无需等待头部任务完成。
全局严格阻塞(窗口外):即使索引为h+w+k的任务已完成,调度器也禁止获取它。
约束推进:只有当头部的任务被消费时,窗口才向前滑动(h→h+1)。这迫使调度器必须等待当前窗口内的“长周期落后任务”,防止训练分布向“快而简单”的样本严重偏移。
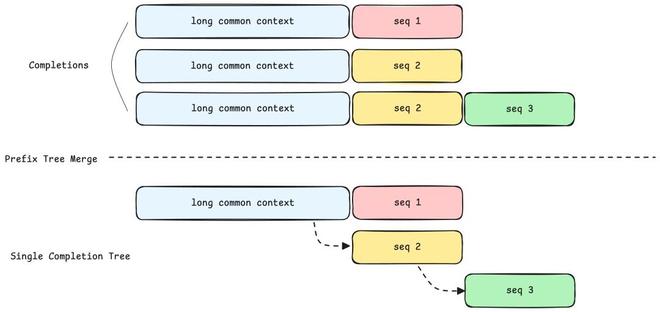
agent的多轮请求间存在很高的上下文前缀重合度,传统方法将每个请求视为独立样本,重复计算公共前缀,浪费了大量的训练算力。
我们提出了prefixtreemerging方案,将训练样本从“线性序列”重构为“树形结构”,下面是具体的数据处理和训练策略:
只要共享基础前缀,completions就能在样本级别合并到一棵前缀树中(即使后续响应或采样分支不同)。
通过利用attentionmask原语(如magiattention)表示不同branch之间的依赖关系,可以保证前向计算在数学上与naive方案完全一致,在计算loss时,我们会把前缀树unmerge为序列的格式,不影响后续的loss计算和指标统计。
该方案消除了冗余的前缀,相比于naive方案实现了约40倍的训练加速,且显著降低了显存开销。
引入异步rl之后虽然rollout阶段算力占比降低到了60%左右,但推理本身还有很大优化空间,我们通过下面的几项优化来加速llm推理:
dynamicmtp:首先我们引入mtp进行推理加速,同时为了保证训练过程中维持draftmodel的高接受率,我们通过top-kklloss在rl过程中持续训练detachedmtphead,与rlpolicy保持对齐。
rollout侧的pd分离:pd分离可以消除moe调度中的pd干扰,为每个实例提供独立的并行和生成策略,在最大化吞吐量的同时优化长尾样本的延迟,防止极端样本阻塞fifoscheduler,并带来较高的offpolicy。
全局l3kvcachepool:在多轮和超长上下文的agent场景下,请求间拥有极高的共享前缀比例,但是局部的kvcache受容量限制,无法达到满意的prefixcache命中率,甚至在rlbatchsize极大的情况下,会发生大量由于驱逐导致的重计算,因此需要支持全局的l3kvcache。同时,forge还通过schedulercost-aware的调度机制,权衡排队延迟和缓存传输时间来动态路由请求,在不使实例超载的前提下最大化缓存局部性。
scalableagentrl算法
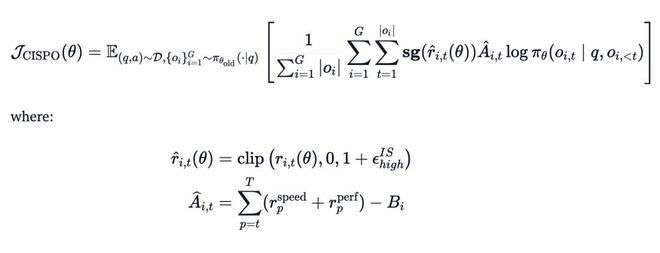
为了解决超长轨迹的信用分配问题并确保稳定,我们设计了一个由三部分组成的复合奖励:
1.过程奖励(processreward):监督agent的中间行为(如惩罚语言混合或特定工具调用错误),提供密集反馈,而不只依赖最终结果。
2.任务完成时间奖励:将相对完成时间作为奖励信号。因为真实延迟不仅取决于token生成,还受工具执行和子agent调用影响,这能激励agent主动利用并行策略、选择最短的执行路径来加速任务。
3.用于降低方差的后续奖励(reward-to-go):长周期任务的稀疏奖励容易引发高梯度方差。我们使用reward-to-go来标准化回报,大幅提高了信用分配的精度,稳定了优化过程。
训出一个真正好用的模型,工程、数据、算法缺一不可,能赶在年前交出这份答卷,离不开背后每一位同事的努力。看到了社区非常多的正向反馈感到非常开心,其实m2.5还有很大的提升空间,内部rl也还在继续跑,性能也在持续涨。目前,m2.5已经全面开源。
huggingface:huggingface.co/minimaxai/minimax-m2.5
github:github.com/minimax-ai/minimax-m2.5
春节马上到了,祝大家新年快乐!