IT之家2月13日消息,英伟达昨日(2月12日)发布博文,宣布在AI推理领域的“token经济学”(Tokenomics)方面,其Blackwell架构取得里程碑式进展。
英伟达在博文中指出,通过推行“极致软硬件协同设计”策略,优化硬件在处理复杂AI推理负载时的效率,解决了随着模型参数膨胀带来的算力成本激增问题。数据显示相比上一代Hopper架构,Blackwell平台将单位Token生成成本降低至十分之一。
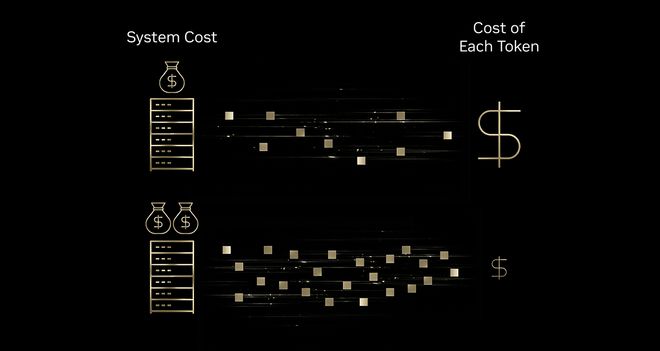
英伟达Blackwell架构将AI推理成本压缩至十分之一
行业落地方面,包括Baseten、DeepInfra、FireworksAI及TogetherAI在内的多家推理服务提供商已开始利用Blackwell平台托管开源模型。
IT之家援引博文介绍,英伟达指出,通过结合开源前沿智能模型、Blackwell的硬件优势以及各厂商自研的优化推理栈,这些企业成功实现了跨行业的成本缩减。
英伟达通过结合开源前沿智能模型使企业成功实现了跨行业的成本缩减
例如,专注于多智能体(Multi-agent)工作流的SentientLabs反馈,其成本效率相比Hopper时代提升了25%至50%;而游戏领域的Latitude等公司也借此实现了更低的延迟和更可靠的响应。
SentientLabs成本效率相比Hopper时代提升了25%至50%
Blackwell的高效能核心在于其旗舰级系统GB200NVL72。该系统采用72个芯片互联的配置,并配备了高达30TB的高速共享内存。这种设计完美契合了当前主流的“混合专家(MoE)”架构需求,能够将Token批次高效地拆分并分散到各个GPU上并行处理。

GB200NVL72系统采用72个芯片互联的配置
在Blackwell大获成功的同时,英伟达已将目光投向下一代代号为“VeraRubin”的平台。据悉,Rubin架构计划通过引入针对预填充(Prefill)阶段的CPX等专用机制,进一步推高基础设施的效率天花板。