🧠别被表面成绩骗了 大模型在科学发现中的
📘 表面成绩很亮眼 研究能力却明显掉队
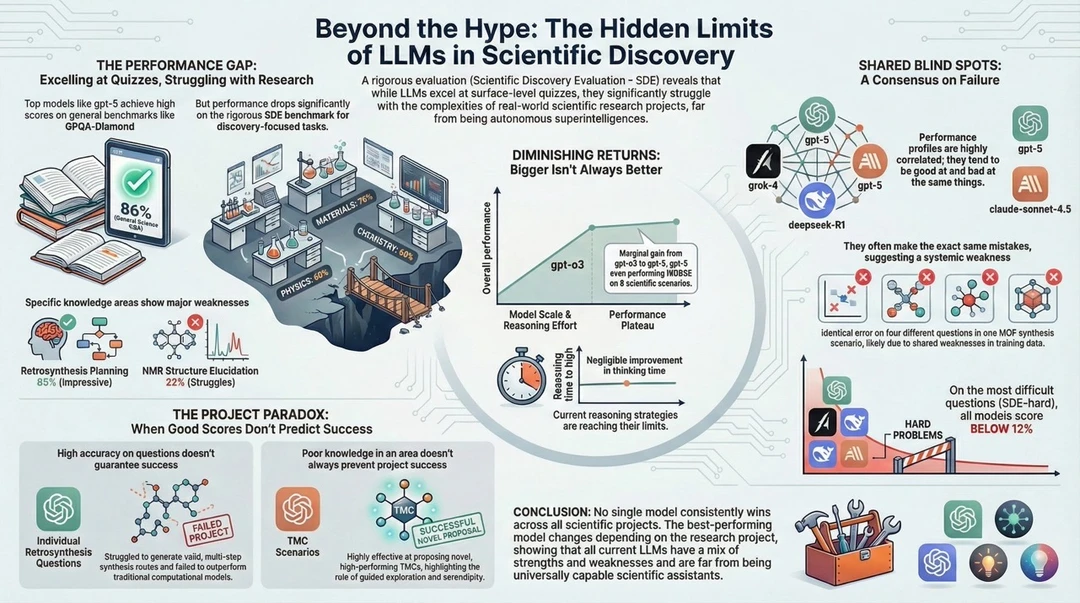
图片首先指出一个核心现象,大模型在答题 测验和通用知识评估中表现非常优秀,例如在通用科学问答中能拿到接近满分的成绩,但一旦进入真正以发现为导向的科研评估场景,整体表现会明显下滑。尤其是在需要长期推理 实验设计和跨学科整合的任务中,能力断层非常明显。
🧪 具体学科暴露出明显短板
在细分领域中,大模型的能力并不均衡。例如在逆向合成规划这类结构化问题上表现尚可,但在核磁共振结构解析 化学反应机理等高度专业且依赖隐含知识的领域中,错误率明显上升。这说明模型更擅长模式匹配,而不是深层科学理解。
⚙️ 规模越大 并不等于越聪明
图中强调了“收益递减”现象。随着模型规模扩大 推理时间拉长,在真实科研任务中的提升却非常有限。即使从较早代模型升级到最新模型,在复杂科学情境下的增益也趋于停滞,说明当前的推理策略本身已经接近上限。
⏱ 多想一会儿 也救不了结果
增加思考时间并不会带来质变。无论是延长推理链条还是增加计算步骤,模型在关键科研问题上的突破都非常有限。这表明问题不在算力,而在推理范式本身。
🧩 不同模型 会犯同样的错误
多个主流模型在同一科研问题上往往出现高度一致的失误。这种“共享盲区”意味着它们的训练数据和学习方式存在系统性缺陷。哪怕模型来源不同,也可能在关键判断上同时失败。
🧱 越难的问题 所有模型一起崩
在最具挑战性的科研测试中,所有模型的成功率都降到极低水平。图中显示,在高难度科学发现评估中,整体成功率甚至低于一成,说明现阶段的大模型距离真正解决前沿科学问题仍然很远。
🧠 单题高分 不代表项目能成功
图片提出了一个重要悖论。即使模型在单个问题上回答准确,也不代表它能完成一个完整科研项目。在需要多步验证 多轮修正的真实研究中,大模型往往无法持续推进
🧪 在引导式探索中反而更有效
当模型被用于辅助探索 提供思路,而不是独立完成科研任务时,效果反而更好。例如在特定实验框架或研究流程中作为辅助工具,它可以提高效率,但仍然需要人类专家做最终判断
🧠 最终结论 非万能科研助手
整张图的结论非常明确,没有任何一个模型能够在所有科学项目中稳定胜出。当前的大模型都同时具备优势与短板,距离真正意义上的自主科学发现系统仍有巨大差距。它们更像是强大的工具,而不是能够独立推动科学进步的研究者