[LG]《Privileged Information Distillation for Language Models》E Penaloza, D Vattikonda, N Gontier, A Lacoste... [ServiceNow] (2026)
知识蒸馏的范式正在发生剧变。当最顶尖的闭源模型选择隐藏其思考链(CoT),只向外界展示最终行动轨迹时,开发者面临一个致命难题:如果看不见巨人的思维过程,我们该如何培养出同样聪明的轻量化模型?
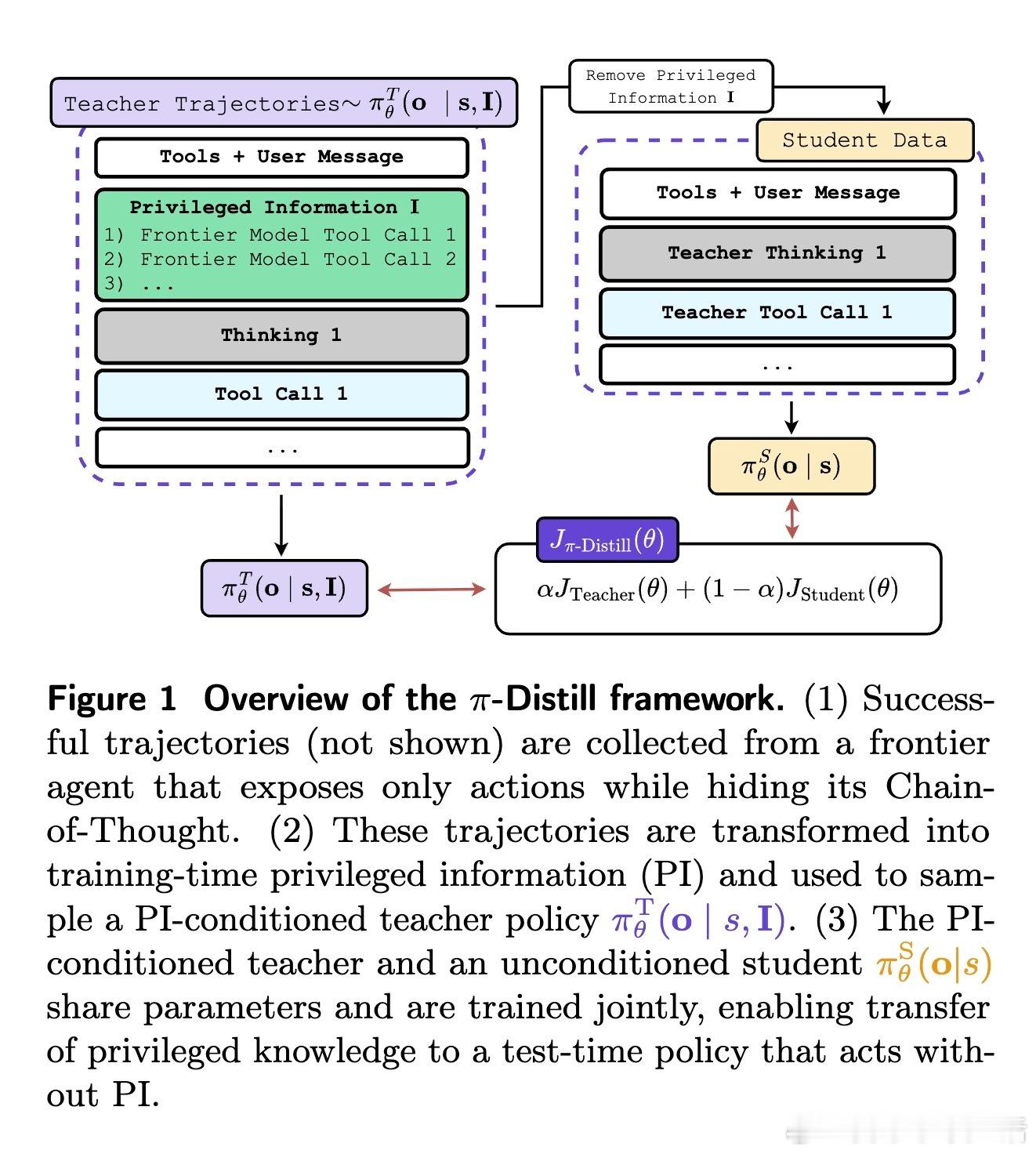
刚刚发布的论文《Privileged Information Distillation for Language Models》为这一困局提供了优雅的解法。研究者提出了一种名为 π-Distill 的框架,其核心逻辑在于利用训练阶段的特权信息(Privileged Information)来弥补推理阶段的信息缺失。这就像是在闭卷考试前,让学生在开卷练习中通过与助教共享大脑,习得处理复杂逻辑的本能。
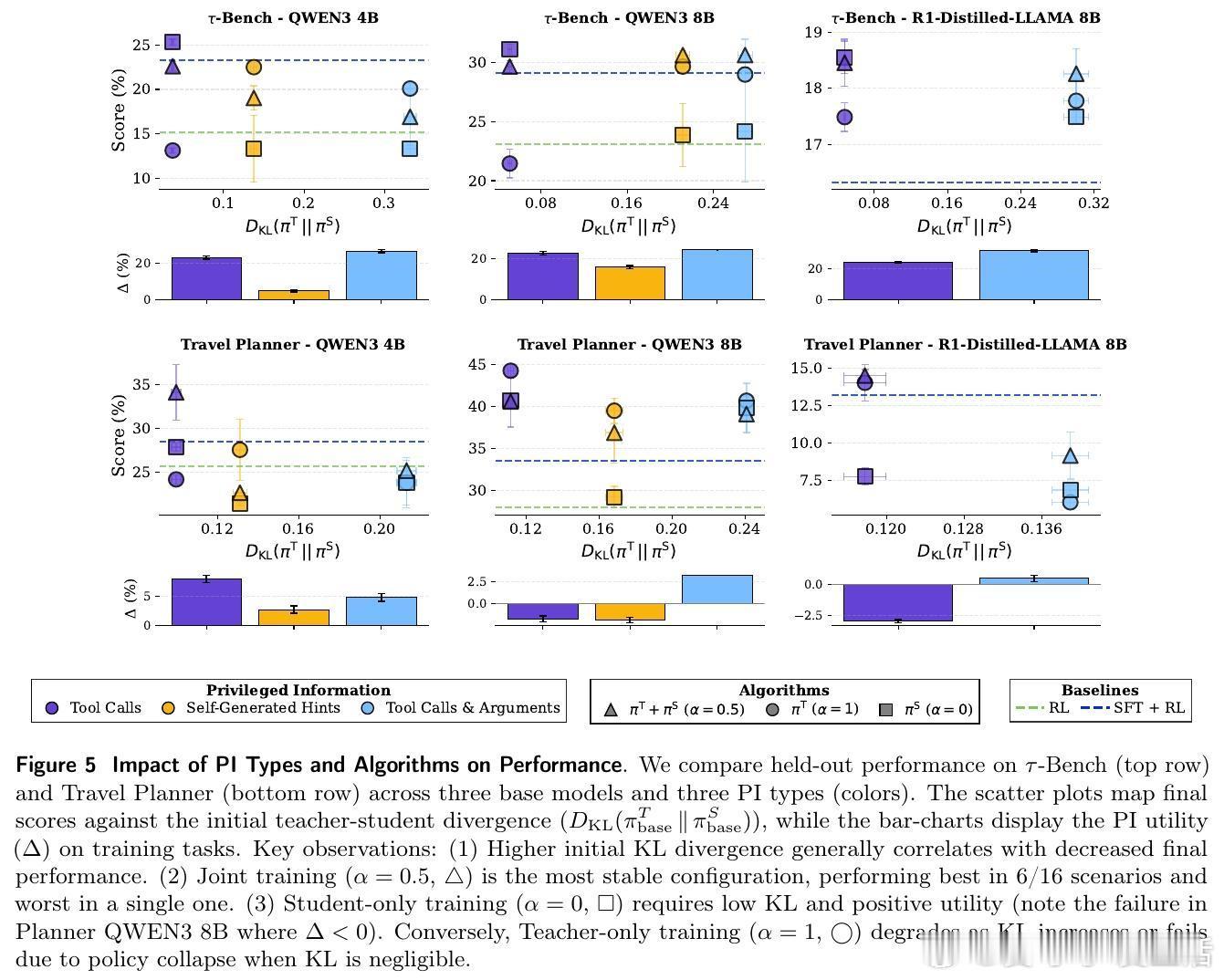
论文的核心贡献在于解决了特权信息的转移挑战。在多轮智能体交互环境中,虽然我们可以观察到成功的结果,却无法得知背后的推理逻辑。π-Distill 通过一种联合教师-学生的优化目标,在同一个模型中同时训练一个拥有特权信息的教师和一个不具备该信息的学生。
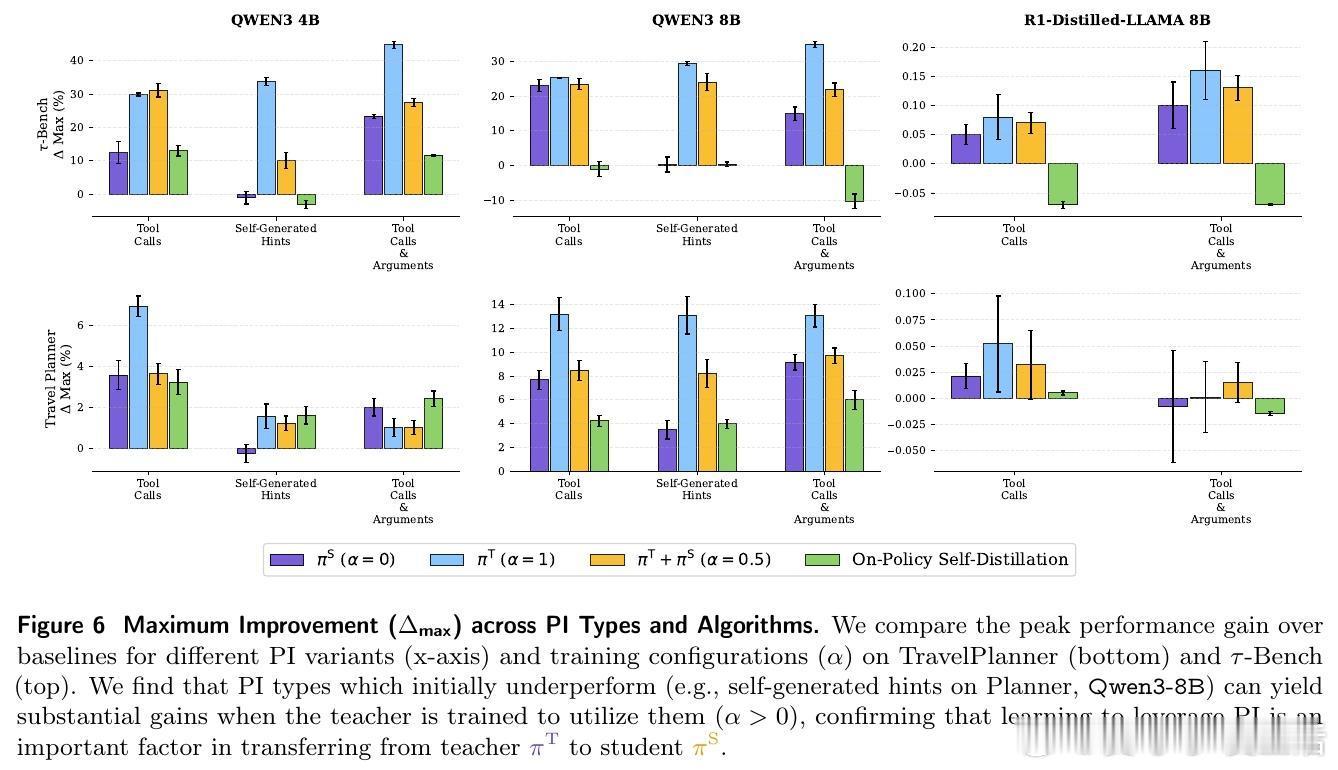
这种设计巧妙地利用了参数共享。教师在训练中学习如何利用特权信息(如工具调用序列或自生成提示)来达成目标,而学生则在相同的参数空间内,学习如何在没有这些信息的情况下复刻教师的高效行为。这种同步训练不仅缓解了传统蒸馏中常见的分布偏移问题,更让模型在训练过程中实现了知识的内化。
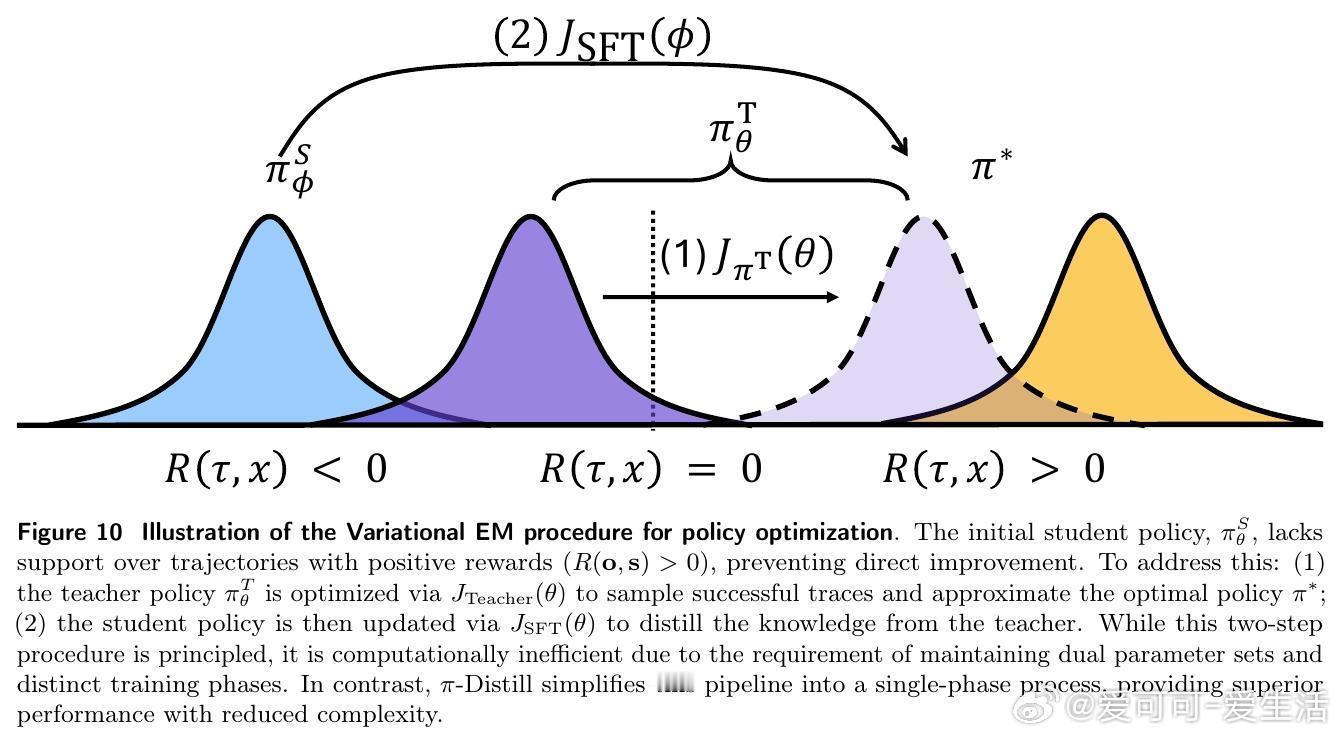
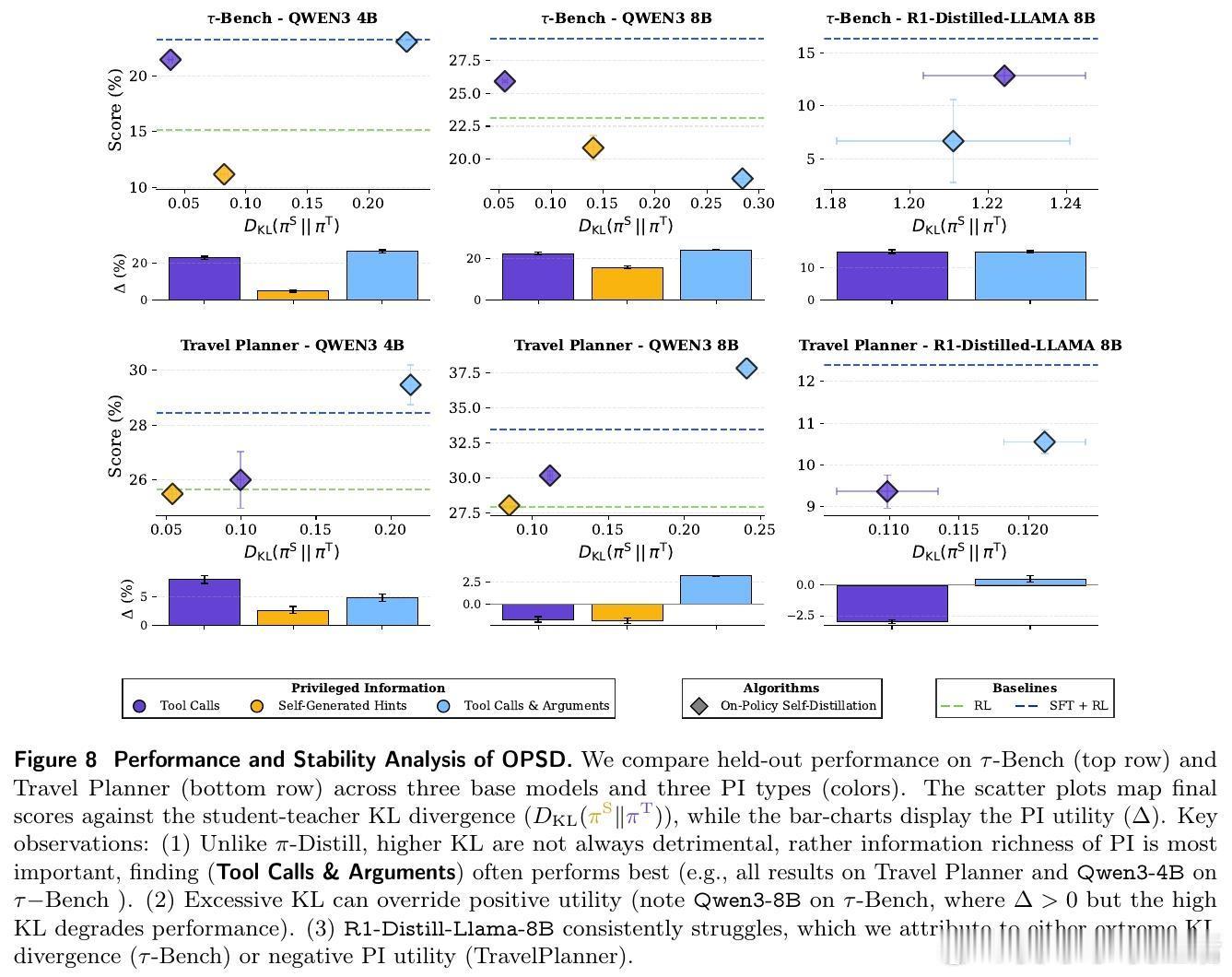
除了 π-Distill,研究者还引入了策略内自蒸馏(OPSD)。这是一种更具动态性的强化学习方法:学生在环境中自主探索,而拥有特权信息的教师则通过 KL 散度作为惩罚项,实时纠正学生的行为偏差。实验数据表明,随着模型规模的增长,这种基于策略内反馈的蒸馏方式在处理复杂任务时表现出极强的韧性。
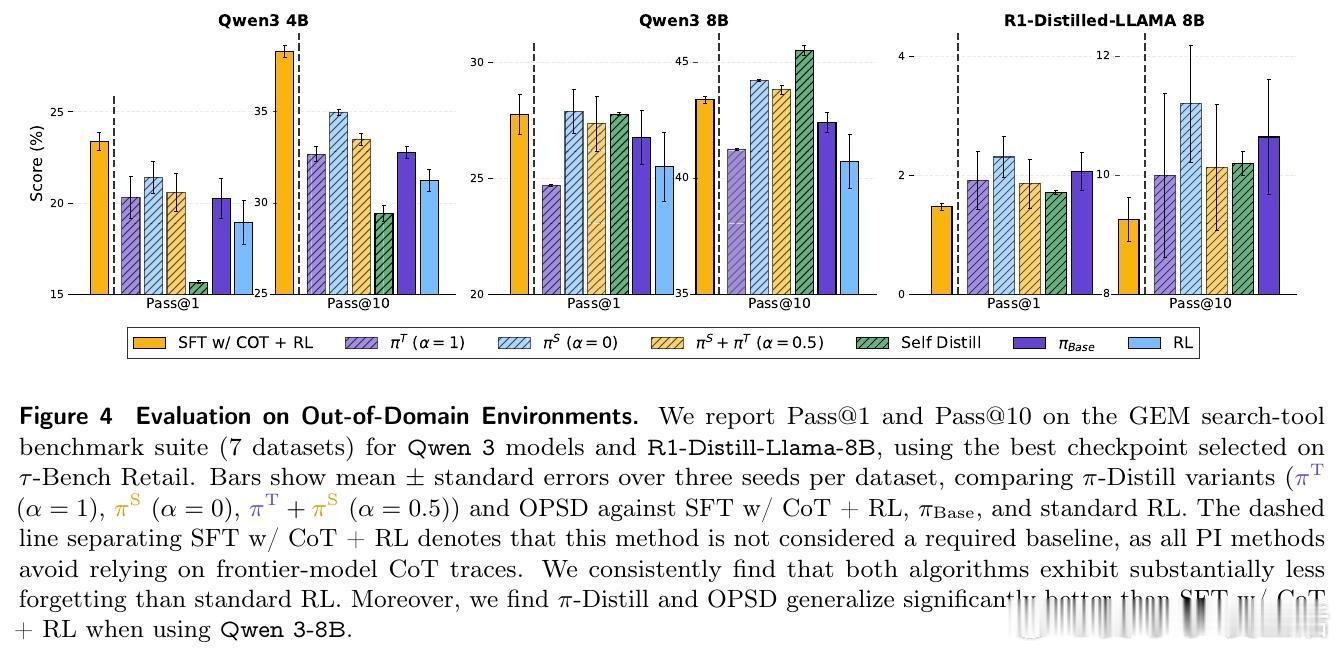
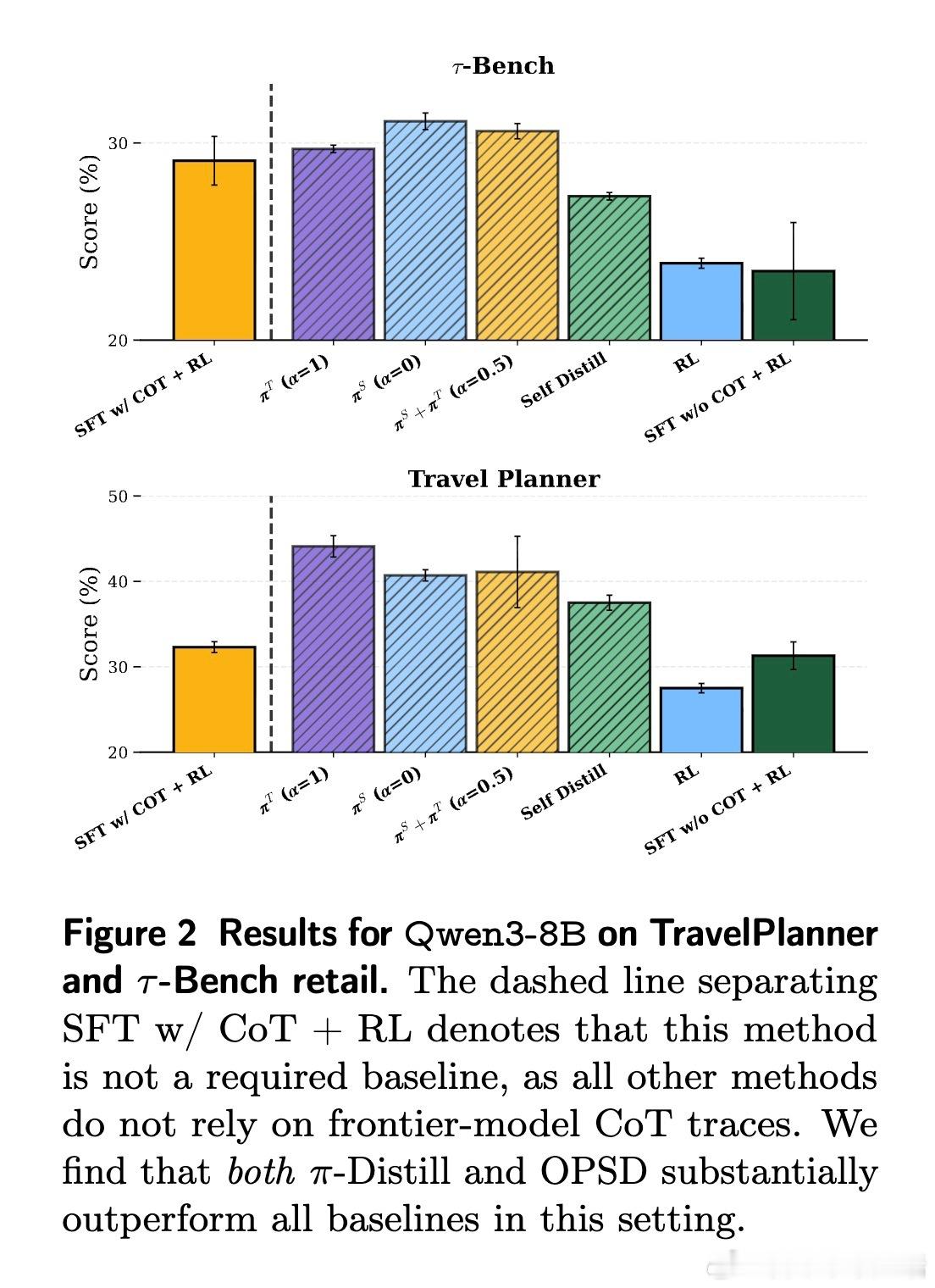
实验结果令人振奋:π-Distill 在 TravelPlanner 和 τ-Bench 等多个严苛的智能体基准测试中,不仅大幅超越了传统的强化学习方案,甚至击败了那些拥有完整思考链监督的行业标准方法。这意味着,即便没有巨人的思维导图,只要我们能巧妙地利用其行动轨迹作为特权信号,轻量化模型依然能进化出极强的推理能力。
这项研究揭示了一个深刻的洞察:有效的学习并非简单的行为模仿,而是在已知与未知之间建立稳定的映射。特权信息在训练中扮演了引导探索的灯塔角色,而参数共享则确保了这种引导能转化为模型底层的认知能力。当特权信息被内化为模型权重时,即便在推理阶段撤走这些拐杖,模型依然能走得稳健且深远。
对于开发者而言,这提供了一条清晰的路径:在蒸馏前沿模型时,不必执着于获取不可得的思考链数据。通过构建合理的特权信号并采用联合训练机制,我们完全可以在黑盒模型的基础上,培养出具备深层推理能力的垂直领域智能体。
论文详情见:arxiv.org/abs/2602.04942代码开源地址:github.com/Emilianopp/Privileged-Information-Distillation