[LG]《EBPO: Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization》K Han, Y Zhou, M Gao, G Zhou... [Meta AI] (2026)
大模型推理能力的提升,正从单纯的规模扩张转向精细的强化学习。DeepSeek 带来的 GRPO 架构虽然通过取消评论者网络实现了高效训练,但在实际操作中却面临一个隐蔽而致命的困境:当模型面对难题全军覆没、所有尝试都得到零分时,相对优势会消失,梯度信号随之枯竭。这意味着昂贵的算力在这些关键的失败步长中被完全浪费了。本文提出的 EBPO(经验贝叶斯策略优化)正是为了打破这种沉默。
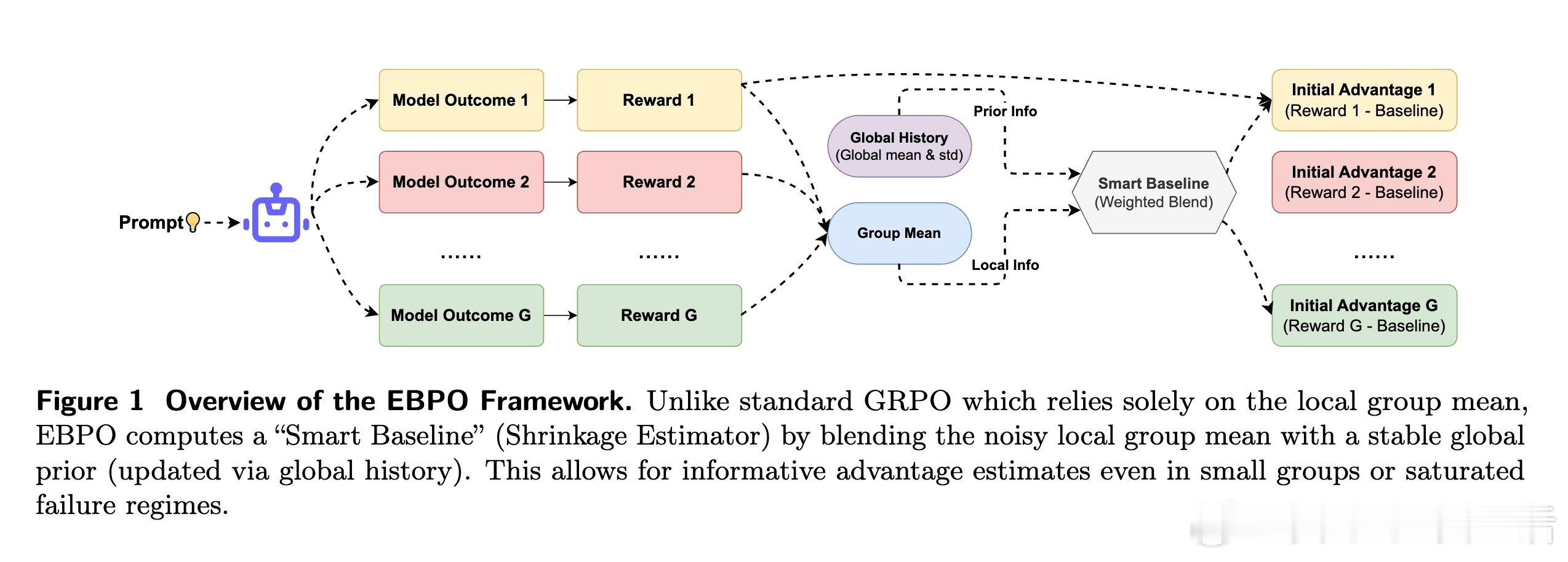
EBPO 的核心思想在于经验贝叶斯中的借力。它不再孤立地看待每一个问题,而是通过收缩估计量,将局部的、高噪声的组内统计数据拉向全局的策略表现分布。这就像一位经验丰富的导师,即便全班学生在某道难题上集体落败,他也能根据以往的教学大数据判断出:这是题目本身超纲,还是学生在基础逻辑上出现了偏差,从而给出精准的反馈。
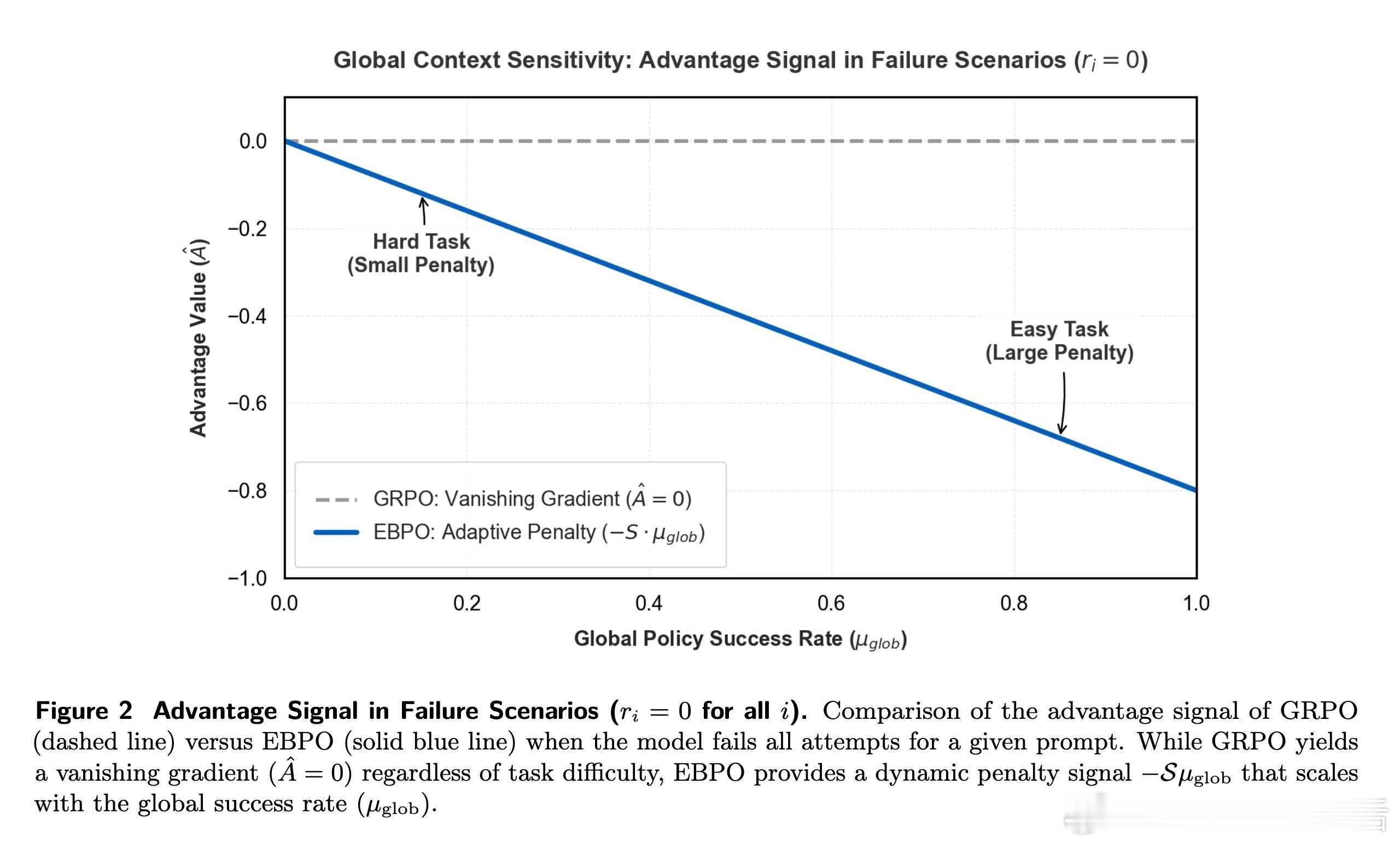
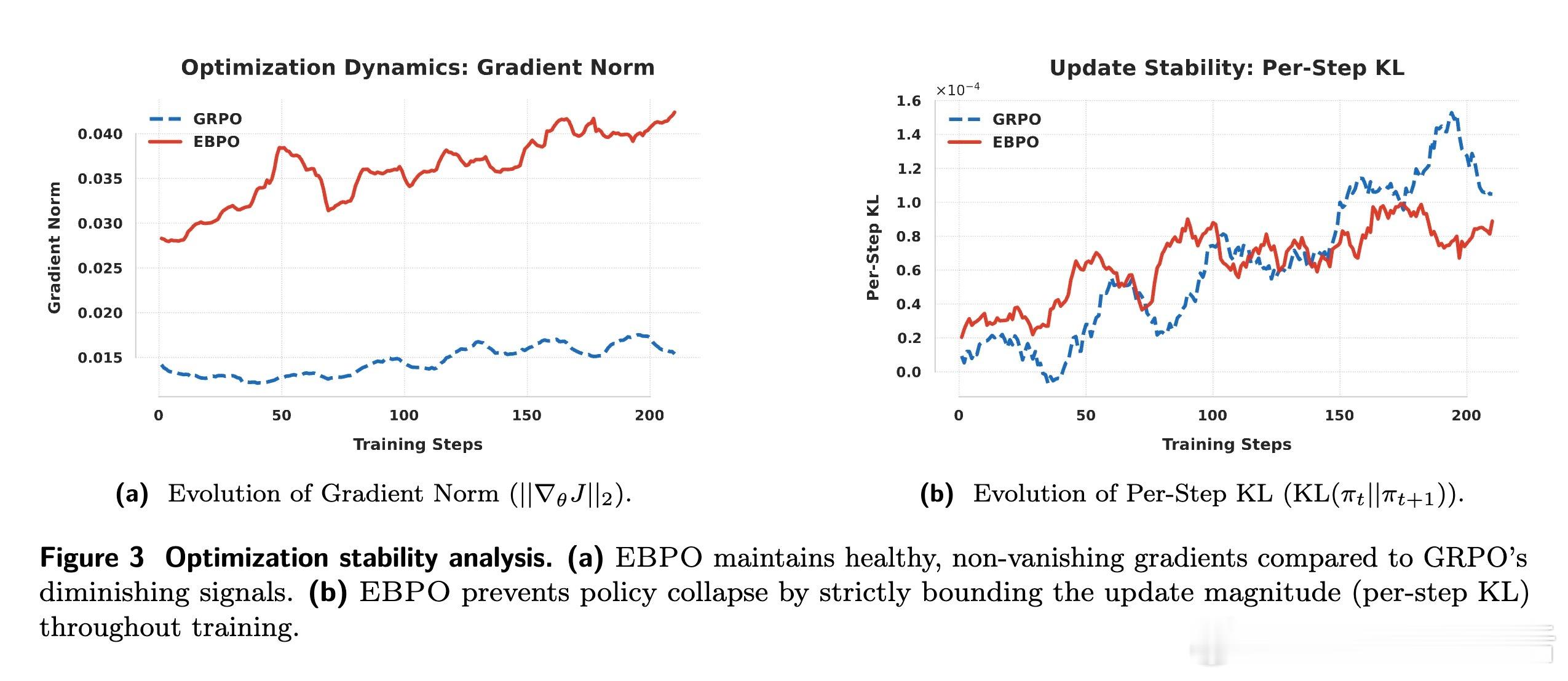
这种借力全局的智慧,是通过 Welford 在线算法动态实现的。EBPO 引入了一个智能基准,利用组内方差与组间方差的比例来动态决定收缩强度。当局部样本不足或奖励信号饱和时,全局先验会迅速介入。理论证明,这种机制不仅能显著降低估计量的均方误差,还能在全零奖励的饱和状态下提供非零的、具有信息量的惩罚信号,确保模型在黑暗中依然能找到进化的方向。
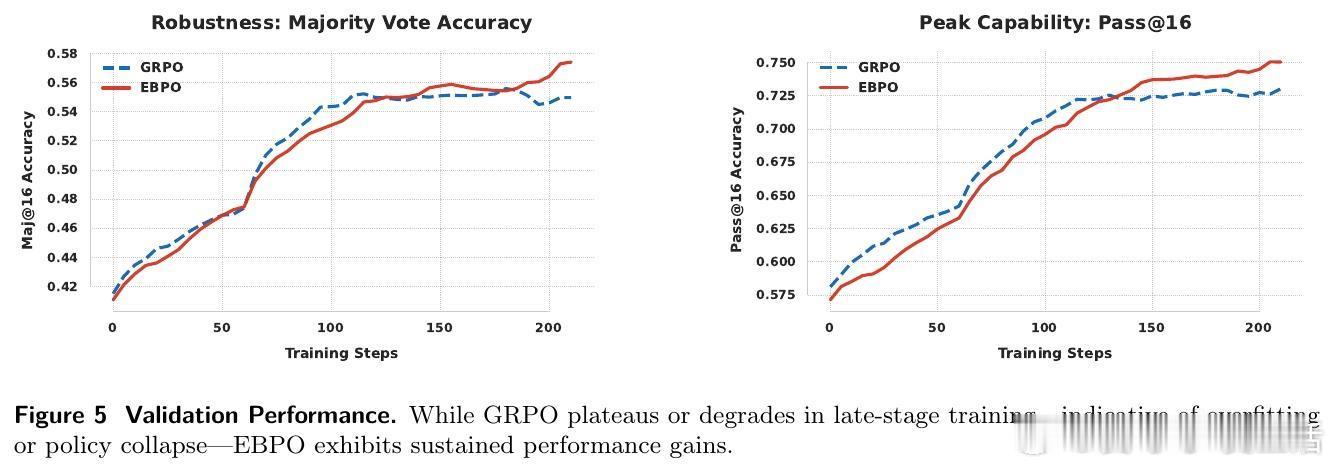
在 AIME 和 OlympiadBench 等硬核数学推理榜单上,EBPO 展现出了极高的稳定性。尤其在资源受限、组大小仅为 8 的极端情况下,它比传统的 GRPO 性能提升了 11% 以上。这意味着 EBPO 极大地提高了样本效率,让模型在更小的计算开销下,依然能获得稳健的梯度流。
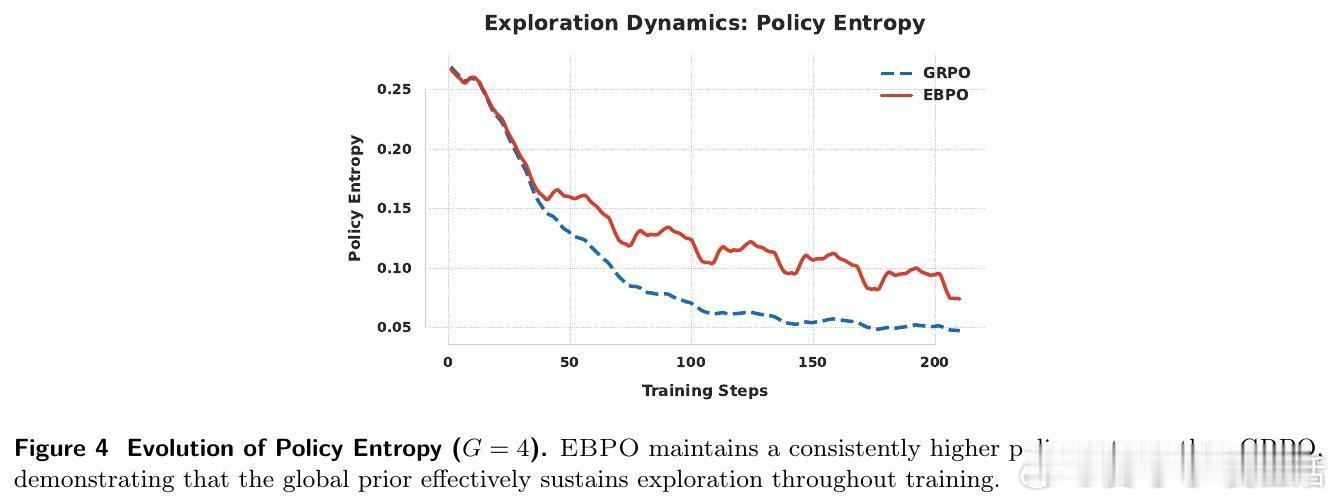
更深层的启发在于其对探索空间的保护。实验观察到,EBPO 能够有效地减缓策略熵的衰减。在强化学习中,过早的收敛往往意味着平庸,而 EBPO 通过全局正则化,让模型在追求高奖励的同时,保持了对未知解法的好奇心。这种在稳定与探索之间的精妙平衡,是其通往竞赛级推理能力的关键。
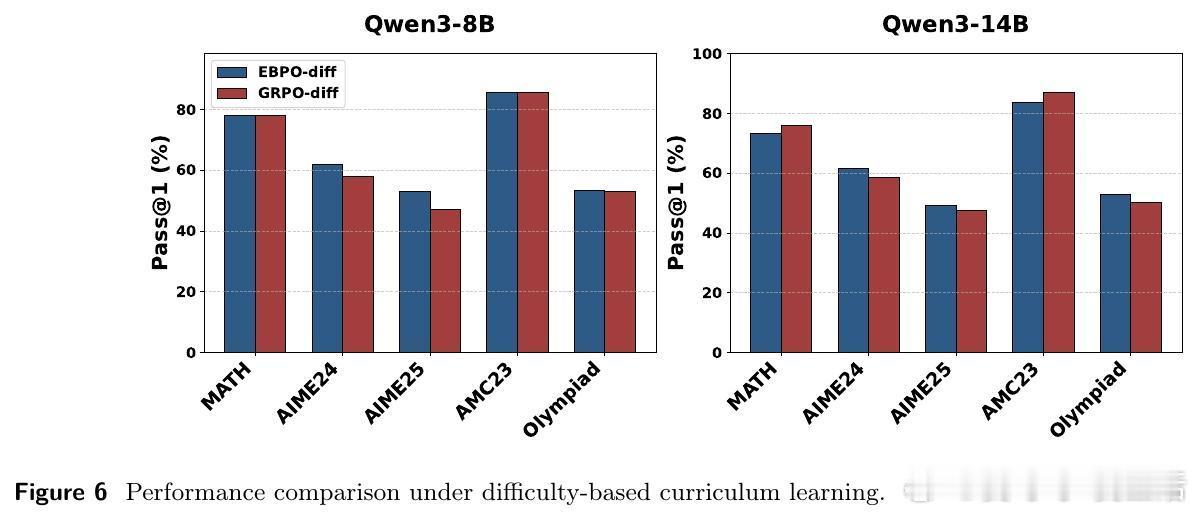
此外,EBPO 与课程学习的结合展示了数据组织的艺术。通过按主题或难度进行聚类采样,经验贝叶斯的先验估计变得更加锐利。这告诉我们:稳定的学习信号并非来自对海量数据的随机吞噬,而在于在相似的语境中建立连贯的认知。真正的稳定不是拒绝波动,而是在全局的秩序中寻找局部的坐标。
论文链接:arxiv.org/abs/2602.05165