GAPO团队 投稿 量子位 | 公众号 QbitAI
程序员们又能少掉头发了!
新研究通过过滤掉训练中的噪声和异常值,显著提升代码大模型在实际编辑任务中的准确性和效率。

在AI辅助编程成为软件开发核心生产力的今天,大语言模型(LLMs)已深度融入代码编辑、调试与优化全流程。
然而,当企业试图用真实复杂用户环境中采集的数据开展强化学习(RL)训练时,一个棘手的实际问题浮出水面:复杂上下文(context)导致大模型的输出答案频繁出现异常内容,即rollout噪声更普遍,使得reward出现异常值(outliers),直接造成优势值(advantage)估计不准确,严重拖累强化学习效果。
上海交通大学、腾讯CodeBuddy等团队联合提出的Group Adaptive Policy Optimization(GAPO)方法,精准直击这一产业落地关键瓶颈,为代码LLM的工业化训练提供了兼具科研创新性与工程实用性的突破方案,引发AI科研界与产业界广泛关注。
真实场景的核心梗阻:复杂上下文→rollout噪声→优势估计失真代码编辑的核心难点在于,真实用户场景的输入提示绝非简单的代码片段,而是包含复杂上下文信息的综合指令——既涵盖代码的模块调用关系、历史编辑记录、指定修改范围,还包含用户模糊的需求暗示。

输入的Prompt结构
这种复杂上下文带来的直接后果是:大模型的输出(rollout)极易出现异常值(outliers),且此类噪声在真实数据中并非个例,而是常态。
1. 复杂上下文为何催生大量rollout噪声?
真实场景的代码编辑任务显示,输入提示长度跨度从1925到24883字符,输出编辑长度从36到833字符,且需兼容Go、Python、Java等10种主流编程语言。
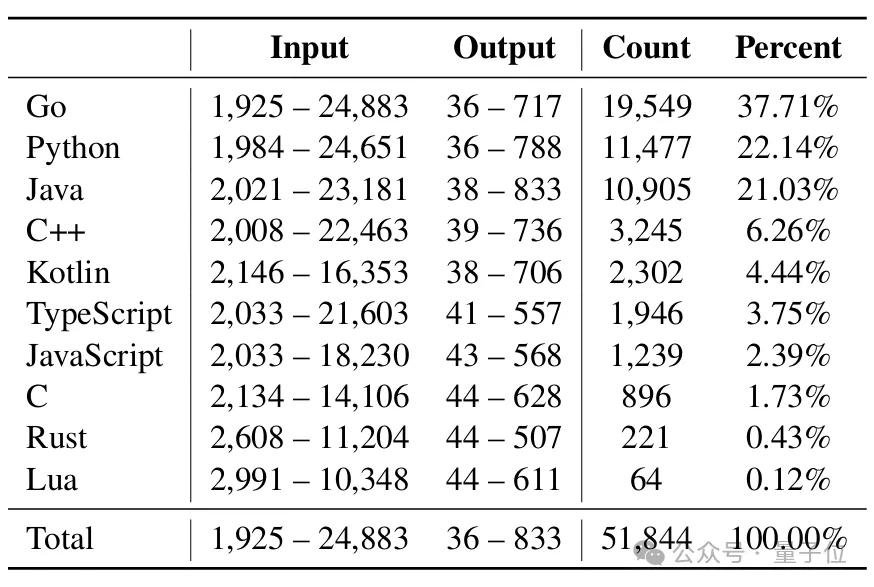
真实世界代码编辑任务的训练数据统计。“Input”和“Output”分别表示输入提示符和输出真实文本长度范围。
更关键的是,每个任务都包含多层级信息:比如Go语言任务中,可能涉及跨文件模块调用、多轮编辑历史的关联,以及用户未明确说明但隐含的性能优化需求。
这种复杂上下文对模型的理解能力提出极高要求,这是模型训练过程中没见过的数据区域,导致模型输出不确定性增加,时常出现“偏离需求的异常编辑”——可能是遗漏关键逻辑、修改无关代码,甚至生成语法错误片段,这些均属于rollout噪声(outliers)。
2. Reward噪声导致优势值估计失灵,使RL信号失真
传统分组相对RL方法(如GRPO、DAPO)的优势值计算依赖群体均值:
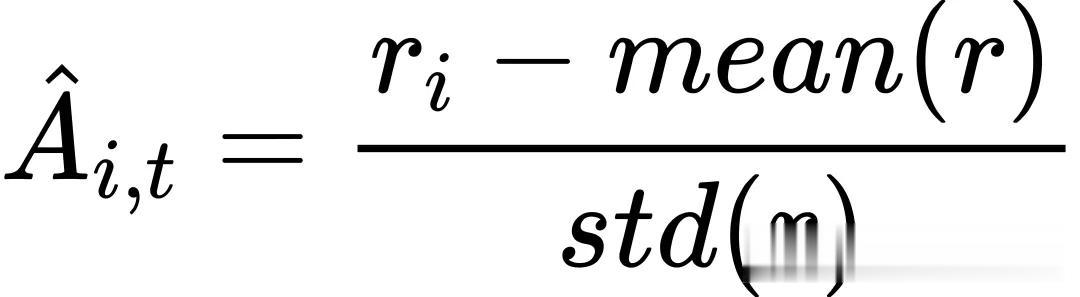
正如下图所示,真实数据的奖励分布中,14.4%呈现右偏、15.5%呈现左偏特征——这种偏斜正是outliers主导的结果:左偏分布中,低奖励区域的outliers拉低均值,导致优势值被高估;右偏分布中,高奖励区域的outliers抬高均值,导致多数有效输出的优势值被低估。
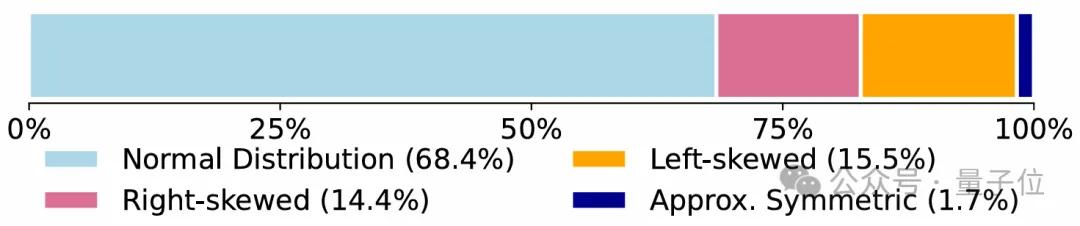
在Qwen2.5-Coder-14B上训练的reward分布统计
更严峻的是,复杂上下文的多样性让噪声分布毫无规律:
不同编程语言、不同编辑场景(如bug修复、功能新增)的outliers特征有很大差异,传统方法的固定均值基准无法适配这种动态噪声。
对企业而言,这意味着投入大量资源采集的真实数据,不仅难以提升模型效果,反而可能因优势估计失真导致模型训练“越训越偏”,实际部署中仍需大量人工校验,违背了AI辅助编程“降本增效”的核心诉求;对科研领域而言,这种真实场景特有的“复杂上下文-噪声-优势估计”连锁问题,长期缺乏针对性突破方案,成为制约代码LLM落地的关键瓶颈。
GAPO的创新突破:精准降噪+稳健估计,突破真实数据训练困局针对“复杂上下文→rollout噪声→优势值估计不准”的核心痛点,GAPO在不改变现有分组相对RL框架核心目标的前提下,仅通过优化优势计算环节,实现“即插即用”的高效突破,其原理可通过论文关键图表直观呈现:
1. 第一步:锁定高信噪比区域,精准过滤outliers
如下图所示,GAPO的核心创新是先从含噪奖励分布中,筛选出不受outliers干扰的“有效信号区”。它将这一问题转化为经典的查找最高密度区间(HDI)求解,通过滑动窗口算法(论文算法1),在每个输入提示的奖励集合中,找到覆盖τ比例(默认0.5)奖励点的最窄区间——这一区间正是最高信噪比(SNR)区域,能最大程度排除复杂上下文催生的outliers(如左偏分布中的低奖励异常值、右偏分布中的高奖励异常值)。
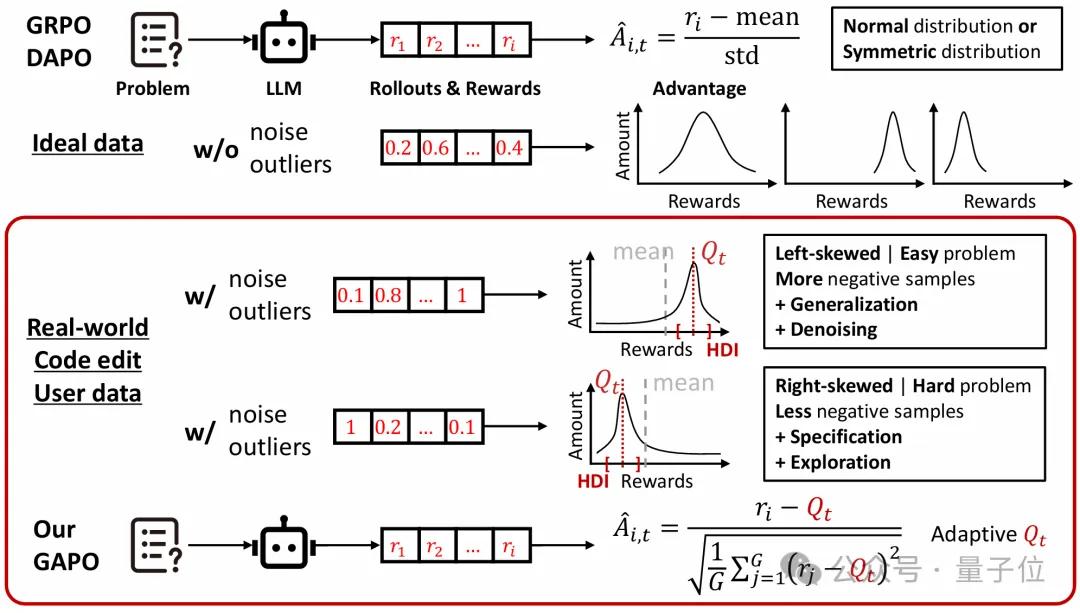
GRPO/DAPO与团队提出的GAPO算法示意图。
上图中rᵢ和Â(i,t)分别表示第i个奖励,以及第t步时一个组内的优势值。Qₜ被定义为自适应最高密度区间(Highest-Density Interval,HDI)的中位数,该区间由每个提示在rollout过程中的奖励分布推导得到。
2. 第二步:用中位数替代均值,稳健估计优势值
在筛选出的HDI区间内,GAPO采用中位数而非均值作为自适应Q值:
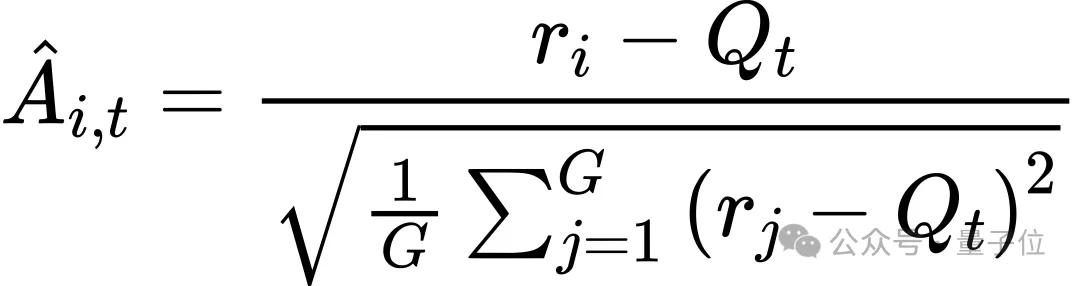
相较于均值对outliers的敏感性,中位数能更稳定地反映“有效输出”的奖励基准:左偏分布(易题)中,Q值高于全量均值,相对产生更多负advantage样本,让这些数据贡献泛化性;右偏分布(难题)中,Q值低于全量均值,相对产生更多正advantage样本,让这些数据贡献提点需求。
Rollout噪声虽然不利于真实advantage估计,但这些noise也是一种模型能力边界的表达,所以研究团队也将其纳入RL过程,以让模型获得更清晰的能力边界,从而擅于处理复杂输入。
3. 工程适配:低复杂度+高兼容性,对接企业真实数据训练需求
GAPO的计算复杂度仅为O(n log n)(主要来自奖励排序),滑动窗口扫描仅需O(n)时间,不会给训练带来额外算力负担。
更重要的是,它仅修改优势计算函数,无需调整RL框架其他模块,仅需少量代码即可集成到verl等主流框架,适配企业基于真实复杂数据的训练流程——无需对数据进行额外降噪预处理,即可直接应对复杂上下文催生的rollout噪声。
实证验证:GAPO让真实数据发挥其价值GAPO的核心价值在于,它让企业采集的真实复杂数据真正发挥效用,其性能优势通过论文丰富的实验图表得到充分验证:
1. 优势值估计更准,模型精度显著提升
如下表所示,GAPO在9个主流LLM(3B-14B参数)上均实现稳定提升:代码专用型模型受益最显著,Qwen2.5-Coder-14B域内(ID)精确匹配准确率达46.25%,较GRPO提升4.35个百分点。
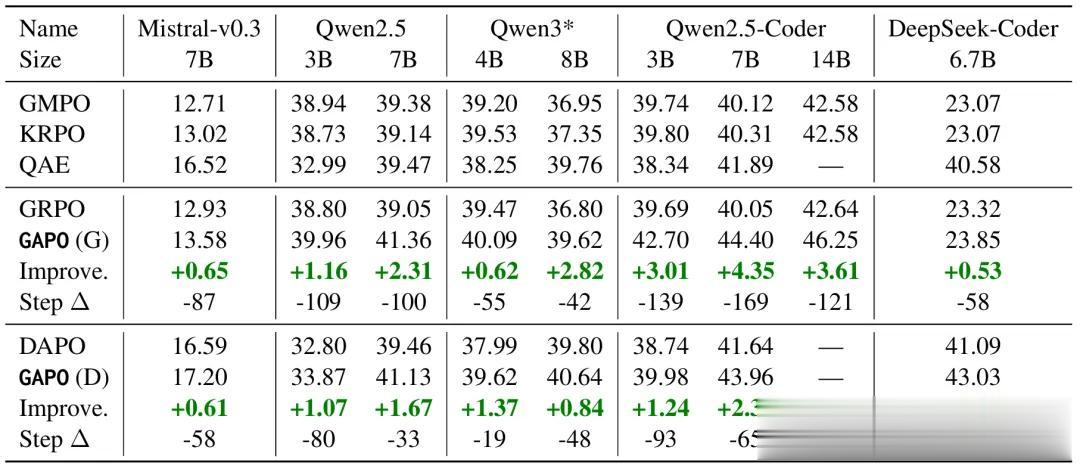
在测试集上九种LLM的精确匹配准确率
跨域(OOD)场景下,Qwen2.5-Coder-7B在zeta数据集上准确率提升5.30个百分点,相对提升达38.89%。这背后正是优势值估计失真问题的有效处理——模型能精准学习真实数据中的有效编辑模式,而非被outliers误导。
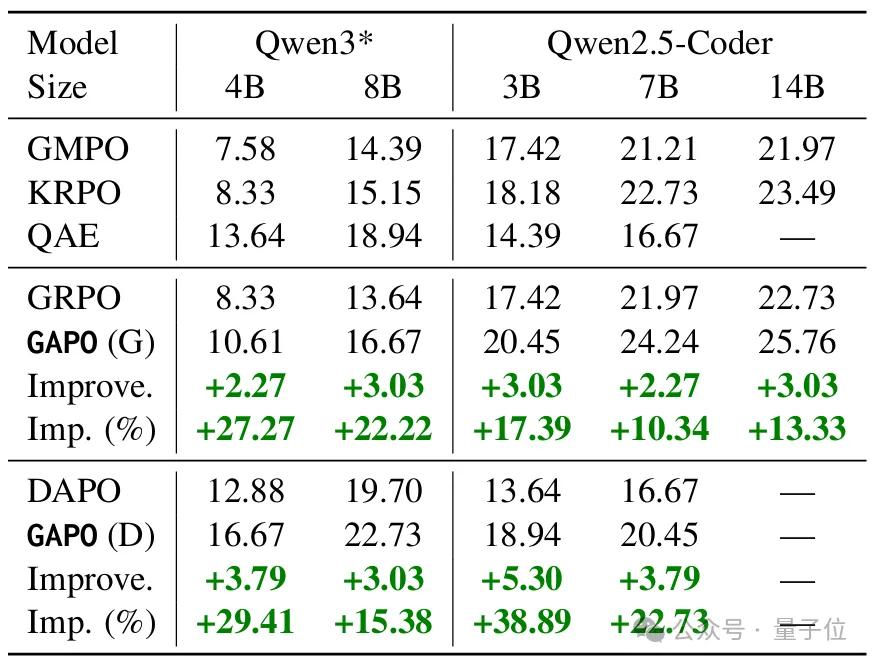
Qwen2.5-Coder和Qwen3在OOD zeta数据集上的精确匹配准确率。
此外,团队的GAPO方法对baseline的提升也比较稳定。
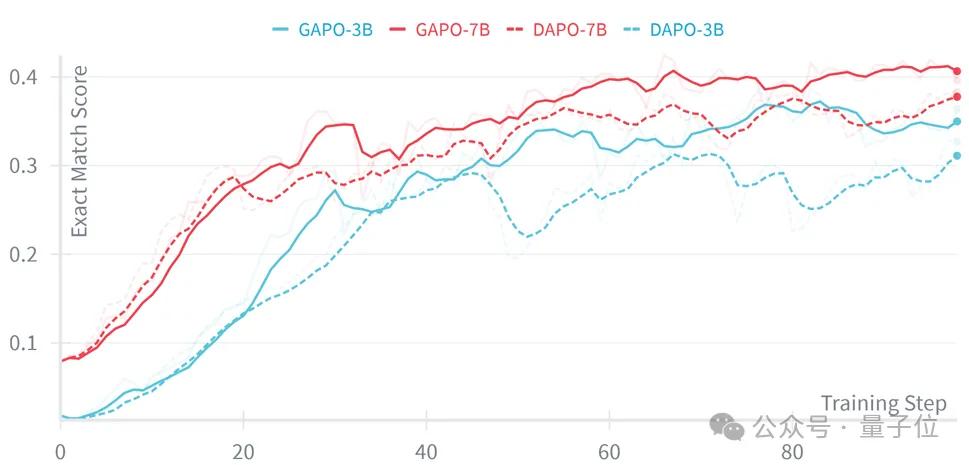
基于Qwen2.5-Coder-3B/7B模型的DAPO算法在测试集上的性能曲线(WB记录)
2. 训练更稳定,算力利用率优化
下图裁剪比例曲线显示,GAPO的pg_clipfrac(梯度更新中概率比被裁剪的比例)显著低于GRPO/DAPO,说明优势值估计更合理,政策更新更准确,能充分利用真实数据中的奖励信息,减少无效迭代。
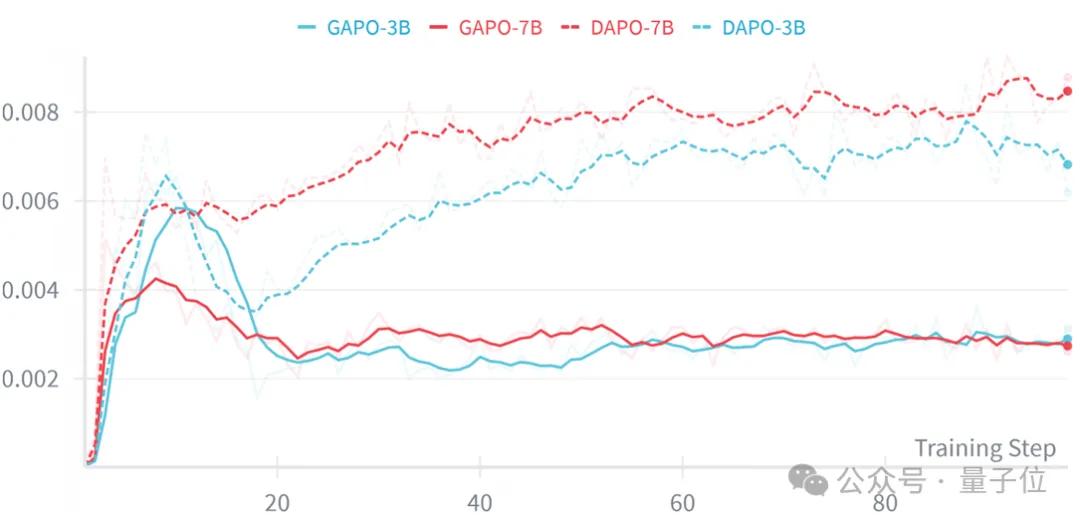
基于Qwen2.5-Coder-3B/7B模型的DAPO算法在训练集上的裁剪比例(Clip fraction)曲线
同时,GPU吞吐量曲线显示,GAPO让3B模型的平均吞吐量提升4.96%,训练后期优势更明显——对企业而言,这意味着用同样的算力,能从真实复杂数据中获得更好的训练效果,从而降低AI模型训练成本。
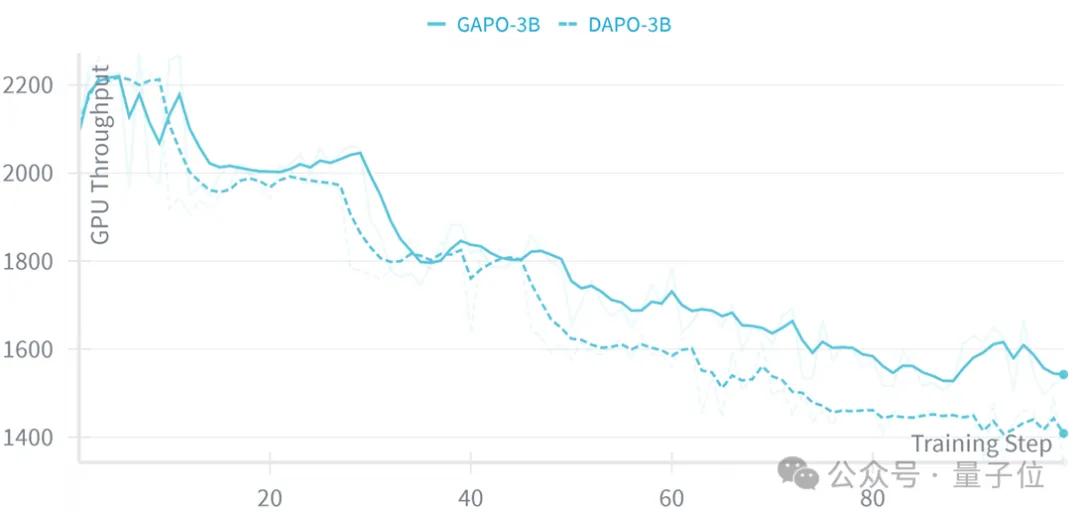
基于Qwen2.5-Coder-3B模型的DAPO算法在训练集上的GPU吞吐量曲线。
结语:让真实数据成为AI辅助编程的“燃料”,而非“包袱”GAPO研究工作精准突破了真实复杂用户环境中“复杂上下文→rollout噪声→优势值估计不准”的连锁难题,让企业采集的真实数据从训练“包袱”变成了提升模型效果的“燃料”。
论文中的图表数据充分证明,该方法在精度、泛化能力、训练效率与硬件利用率上均实现突破,既为AI科研人员提供了针对真实场景噪声问题的新技术思路,也为企业降低AI辅助编程落地门槛、提升研发效率提供了切实可行的方案。
随着GAPO代码的开源,研究团队也期待更多科研人员与企业开发者参与探索,让AI辅助编程更深入地融入软件开发全流程,推动软件产业向更高效、更智能的方向发展。
论文标题:
GAPO:Robust Advantage Estimation for Real-World Code LLMs论文链接:
https://arxiv.org/pdf/2510.21830开源代码:
https://github.com/TsingZ0/verl-GAPO
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态